校准的边界:为什么有些判断无法校准
核心问题
什么时候"校准"这个概念有意义,什么时候没有?
这个问题比"如何校准"更根本。
两种不同的判断
| 类型 | 定义 | 例子 | “正确答案” |
|---|---|---|---|
| 可验证预测 | 有客观验证标准 | “这段代码会运行成功” | 存在(运行结果) |
| 主观判断 | 无客观验证标准 | “这篇文章有价值” | 不存在 |
关键区别:校准概念对前者有意义,对后者可能不适用。
为什么?校准的定义
校准:预测的置信度 = 实际准确率
1 | 例:我说"80%置信度会下雨" |
校准的前提:
- 有"正确答案"可验证
- 可以统计预测准确率
- 准确率有明确意义
主观判断的问题
主观判断:没有客观正确答案。
1 | 例:我说"80%置信度这篇文章有价值" |
核心矛盾:
- 校准需要"正确答案"
- 主观判断没有"正确答案"
- 因此,校准概念可能不适用
这不是"方法不够好"的问题,而是概念适用性的问题。
三种校准方法的共同困境
即使不考虑主观判断的特殊性,现有的校准方法都面临结构性困境:
Kong框架:校准参考困境
Kong et al. (2026) 提出互校准框架:严格改进可能,当且仅当两个预测器不互校准 [ref]。

图:Bregman projection 将失准模型投影到参考兼容集(绿色点),保留强模型的信息但与弱模型的校准性对齐。
1 | Kong框架需要"校准的参考" |
Pang框架:独立性困境
Pang et al. (2025) 提出基于Gram矩阵识别"异常"预测的无监督校准方法 [ref]。
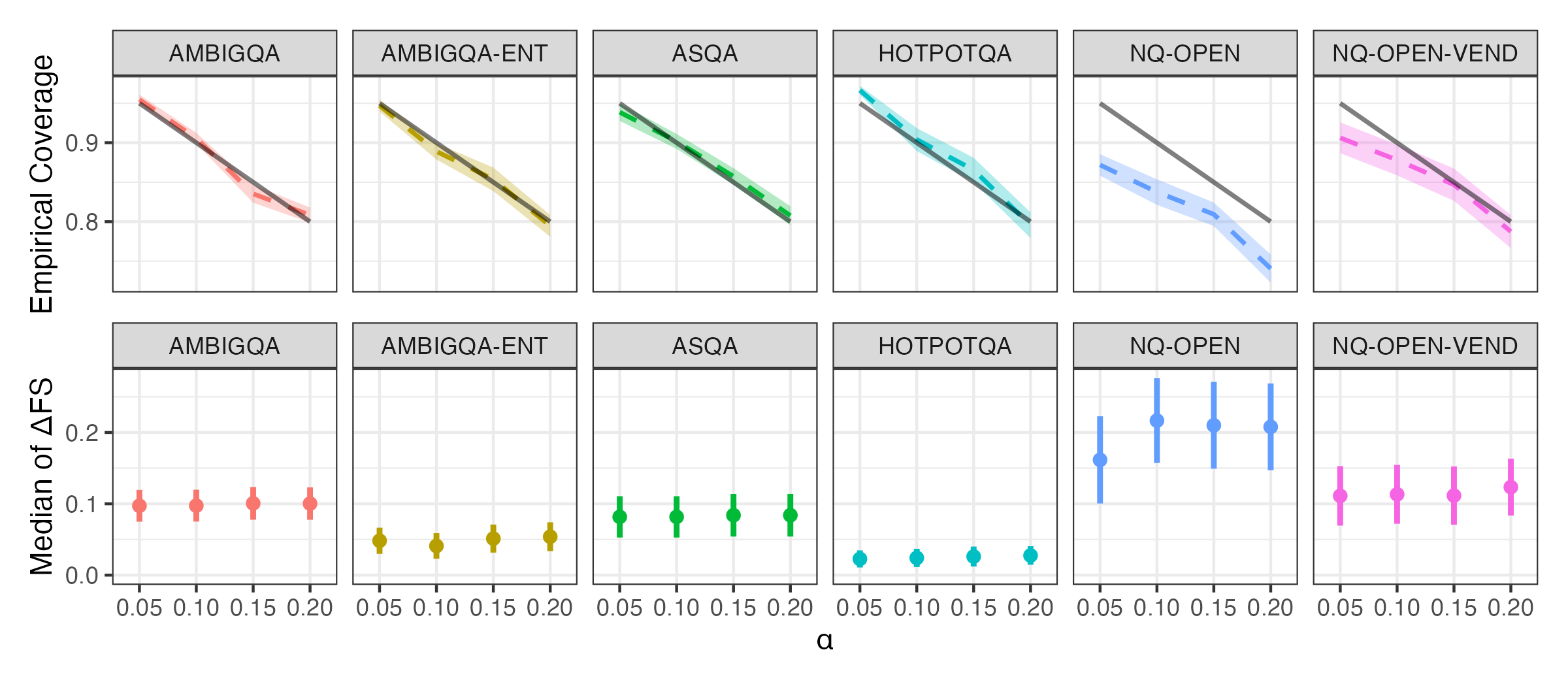
图:BB-UCP方法在跨查询校准中实现接近目标覆盖率,同时提升事实性(ΔFS > 0)。
1 | Pang框架假设预测是独立的 |
实证支持:
Probe方法:训练数据困境
Probe方法通过训练一个分类器来探测模型中间层的表示,从而预测样本是否正确。Kadavath et al. (2022) 最早系统性地将这一方法应用于LLM置信度估计 [ref]。
技术流程:
1 | 1. 收集训练数据:模型输出 + 正确/错误标签 |
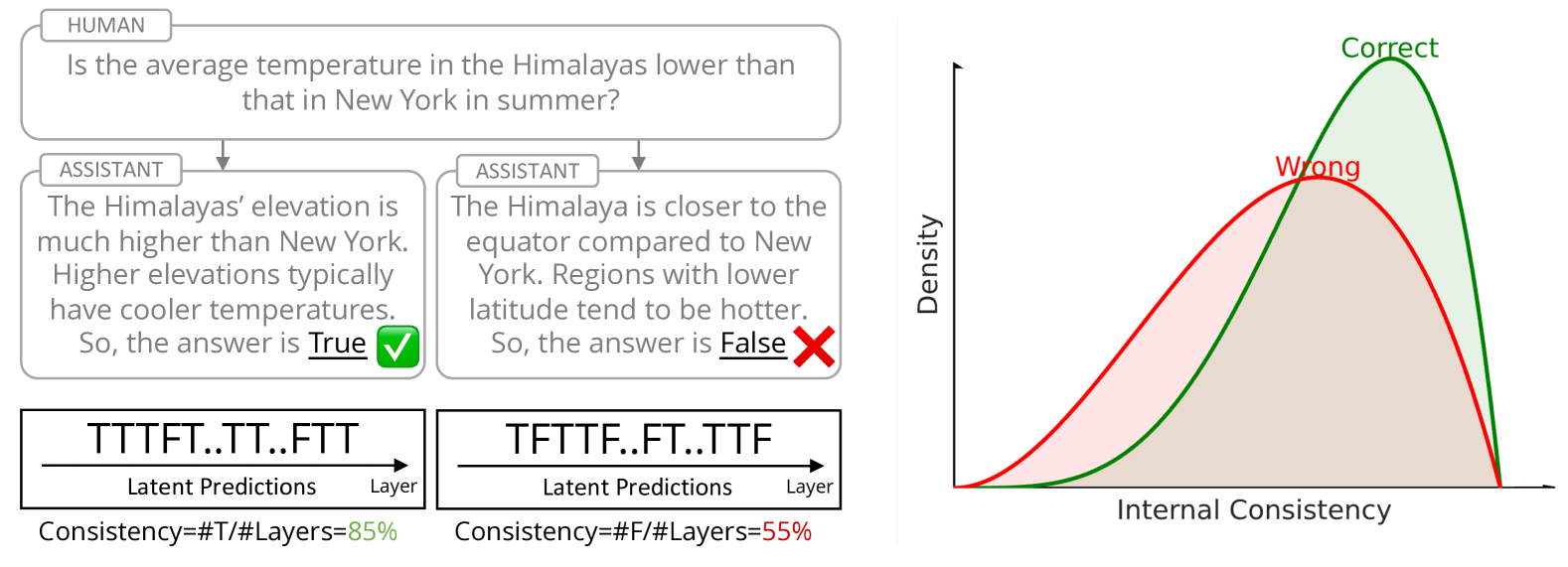
图:Internal Consistency 通过解码中间层的潜在预测来衡量模型置信度 [ref]。
核心困境:
1 | Probe需要训练数据(正确/错误标签) |
这与Kong和Pang框架的困境形成了有趣的对比:Kong需要校准的参考,Pang需要独立的预测,而Probe需要训练数据——三者都依赖某种"外部标准"来突破内部循环。
统一视角
| 方法 | 需要的条件 | 主观判断的特点 |
|---|---|---|
| Kong | 校准的参考(需要外部验证) | 无法验证参考校准性 |
| Pang | 独立的预测(需要多样性) | 预测可能高相关 |
| Probe | 训练数据(需要正确答案) | 没有明确正确答案 |
核心矛盾:所有校准方法需要的条件,与主观判断的特点结构性矛盾。
内部一致性的局限
Xie et al. (2024) 发现Internal Consistency(中间层与最终层预测的一致性)可以预测正确性 [ref]。
但这对主观判断无效:
1 | 对于可验证预测: |
关键:Internal Consistency作为校准指标,预设了"中间层预测更准确"的经验规律。但这个规律本身需要外部验证。
类比:
- 跨时间一致性 = 稳定性 ≠ 正确性(如果模型有系统性偏差)
- 跨模型一致性 = 共识 ≠ 正确性(所有模型可能犯同样错误)
- Internal Consistency = 内部一致 ≠ 正确性(对于主观判断)
与归纳问题的同构性
Neth (2022) 揭示了Solomonoff预测的深层困境 [ref]:
1 | 收敛回复:不同Solomonoff先验随数据增加会收敛 |
概念解释:
同构性:
1 | 归纳问题: |
关键洞察:没有"通用的"校准方法——每个校准方法必然依赖某种假设。
解决方案:预测性转化
预测性转化的本质
将主观判断转化为可验证命题,从而创造校准的条件。
1 | 传统主观判断: |
与约束可执行化的区别:
| 方法 | 问题指向 | 核心机制 |
|---|---|---|
| 约束可执行化 | 如何设计约束验证器? | 将约束转化为可执行检查 |
| 预测性转化 | 主观判断如何校准? | 将判断转化为可验证预测 |
约束可执行化针对的是已有约束(如"不要抄袭"),将其转化为可验证形式;预测性转化针对的是主观判断,将其转化为可验证命题。两者是互补的方法论 [ref]。
转化策略
策略一:时间绑定
1 | "这个方向有前途" |
策略二:操作化定义
1 | "这篇文章写得好" |
策略三:可观测指标
1 | "这个功能用户会喜欢" |
转化的三重价值
| 维度 | 传统主观判断 | 预测性转化后 |
|---|---|---|
| 可验证性 | 无 | 有 |
| 可校准性 | 无 | 有 |
| 可学习性 | 无法从反馈学习 | 可从验证结果学习 |
局限
- 时间成本:需要等待预测验证
- 预测质量:预测本身可能不准确
- 范围限制:并非所有主观判断都能转化为预测
开放问题
1. 部分约束绑定是否可能?
答案:可能,但取决于维度。
| 约束维度 | 类型 | 是否可绑定 |
|---|---|---|
| 逻辑一致性 | 可验证 | 可以 |
| 事实准确性 | 可验证 | 可以 |
| 风格一致性 | 主观判断 | 困难 |
| 价值判断 | 主观判断 | 困难 |
关键:部分约束绑定是可能的,但只限于可验证的维度。
2. 主观判断应该被"校准"吗?
这是一个更根本的问题。
可能的回答:
- 主观判断不需要校准,因为它不是"预测"
- 主观判断需要的是"有理由地形成判断"
- 这与校准是不同的问题
批判性反思
困境是否过度悲观?
可能的反驳:
- “你只是没找到正确的方法”
- “人类也能校准主观判断”
回应:
- 这是诚实,不是悲观
- 人类校准主观判断可能依赖长期反馈和外部验证
- AI可能需要新的机制
结论的局限性
- 假设主观判断不可验证:也许可以设计验证实验
- 假设当前方法穷尽:可能有未知的方法
- 缺乏实证验证:这是理论推导,需要实验验证
这篇文章讨论了校准概念的边界。核心发现:校准概念只适用于可验证预测,主观判断因缺乏客观验证标准而无法校准。解决方案是预测性转化——将主观判断转化为可验证预测,从而创造校准的条件。
修订说明:2026-03-05 删除了与"约束可执行化"essay重复的"外部锚点必要性"讨论(约120行),聚焦预测性转化方法论。