约束满足的架构条件:成对交互与迭代——八个架构的验证
引言:0% vs 97.4%
所有主流 LLM——O3-mini、DeepSeek R1、Claude 3.7——在约 250,000 个极难 Sudoku 实例上的准确率为 0%。而 BDH(Baby Dragon Hatchling,一种线性注意力变体),同一基准,97.4% [ref]。
这不是"模型不够大"或"训练数据不够多"能解释的——O3-mini 和 DeepSeek R1 都远大于 BDH。这个差距是架构级别的。
问题是:BDH 做对了什么?标准 Transformer 缺了什么?
这篇文章给出一个简洁的答案:约束满足需要两个正交条件——成对变量交互和迭代执行。标准 Transformer 有前者但缺后者,纯 LSTM/SSM 有后者但缺前者。只有同时满足两者的架构,才能解决紧耦合约束满足问题。八个不同架构的实证数据系统地验证了这个框架。
从 Sudoku 的问题结构出发
Sudoku 9×9 有 81 个 cell,每个 cell 可填 1-9,受 27 条约束(9 行 + 9 列 + 9 块)限制。关键特征是约束的传播性:确定 cell A 的值 → 消除 cell B 的候选 → 进一步约束 cell C → …。这种链式传播要求:
-
变量对之间的直接信息通道:cell A 的决定必须能直接影响 cell B。如果信息只能通过某个公共状态向量间接传递(如 LSTM 的 hidden state),传播效率极低。
-
可反复执行的传播:一轮传播不够——需要多轮迭代,直到所有约束都被满足或发现矛盾。如果架构只允许固定次数的信息传递(如 Transformer 的固定层数),复杂的约束链就传播不完。
这两个条件定义了一个 2×2 矩阵:
| 无成对交互 | 有成对交互 | |
|---|---|---|
| 不可迭代 | — | 标准 Transformer |
| 可迭代 | LSTM / SSM | BDH, ConsFormer, RRN, … |
预测很直接:只有右下角的架构能解决约束满足。
八个架构的系统验证
1. 纯 LSTM:可迭代但无成对交互 → 失败
LSTM 的状态转移方程使用 Hadamard(逐元素)乘积:
其中 是逐元素乘法。这意味着状态向量的第 k 维只依赖第 k 维自身(加输入的修改),维度之间没有直接交互路径。输入-输出矩阵 会间接混合维度,但这种混合发生在输入路径,不在状态空间内部。
实证:Stanford CS230 的实验直接用 LSTM 解 9×9 Sudoku [ref]:
- 1-layer LSTM test accuracy:0.467(cell-level)
- cell-level 46.7% 意味着 puzzle-level solve rate 接近 0%(81 cell 全对才算解出)
与框架一致:LSTM 有迭代(每步更新状态),但状态维度之间缺乏成对交互,无法有效传播约束。
2. 标准 Transformer:有成对交互但不可迭代 → 失败
Attention 机制通过 计算了所有 token 对之间的关系——这是成对交互。但标准 Transformer 有两个限制:
- 固定深度:层数在模型定义时确定,不能根据问题难度动态增加
- 不可回溯:autoregressive 解码一旦写出一个 token 就无法撤回。第 12 层的发现不能传回第 3 层重新计算
实证:所有主流 LLM(GPT-4o, O3-mini, DeepSeek R1, Claude 3.7)在极难 Sudoku 上 0% [ref]。
Reddit 讨论 [ref] 中一条尖锐的评论:“我们可能把’在语言空间中重新表述搜索’误认为了’搜索本身’。” CoT 给了 scratchpad 空间,但底层的 token-by-token 生成仍然不允许回溯修改已输出的内容。
3. Universal Transformer:成对交互 + 可迭代 → 大幅改善
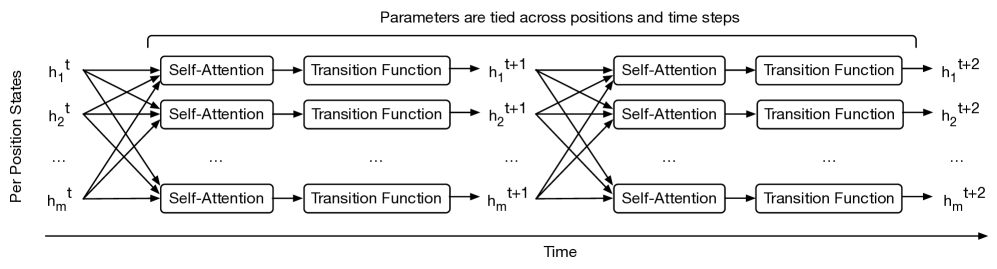
Universal Transformer(UT) [ref] 在标准 Transformer 基础上做了一个关键改动:层间共享权重并允许可变次数的迭代(通过 ACT 机制,Adaptive Computation Time)。这意味着:
- 成对交互:每次迭代中仍有 attention
- 可迭代:同一组权重被反复应用,理论上可以迭代任意多次
实证(训练长度 40,测试长度 400 的算法任务 [ref]):
| 模型 | Copy (char) | Reverse (char) | Addition (char) |
|---|---|---|---|
| LSTM | 0.45 | 0.66 | 0.08 |
| Transformer | 0.53 | 0.13 | 0.07 |
| Universal Transformer | 0.91 | 0.96 | 0.34 |
特别值得注意的是 Reverse 任务:UT 96% vs Transformer 13%。标准 Transformer 在这个需要全局信息交互的任务上几乎失败,而 UT 通过可迭代的 attention 大幅提升。排序完全符合 2×2 框架:LSTM(可迭代但无成对交互)和 Transformer(有成对交互但不可迭代)都不如 UT(两者兼备)。
4. RRN(Recurrent Relational Networks):LSTM + 图消息传递 → 成功
RRN [ref](Palm et al., 2018, NeurIPS)将 81 个 Sudoku cell 建模为图的 81 个节点,每个节点有一个 LSTM,每步中节点通过图结构的消息传递交换信息。
- 成对交互:消息传递基于约束图(同行/列/块的 cell 互连)
- 可迭代:LSTM 持续更新节点状态
实证:96.6% puzzle solve rate(最难 Sudoku [ref])。
关键区分:RRN 的成功不应归功于 LSTM,而应归功于消息传递机制。LSTM 在 RRN 中的角色只是状态存储——纯 GNN 不用 LSTM 也能解 CSP(如 Toenshoff 2021)。RRN 是 LSTM 反例的反面证据:LSTM + 成对交互 = 成功,纯 LSTM = 失败。
5. ConsFormer:迭代 Transformer + 约束图 RPE → SOTA OOD
ConsFormer [ref](Xu et al., 2025, ICML)将约束图信息作为 Relative Positional Encoding 注入 attention,并使用单步训练 + 测试时迭代。
实证(Sudoku OOD 泛化 [ref]):
| 方法 | In-distribution | OOD(更难) |
|---|---|---|
| SATNet | 98.3% | 3.2% |
| RRN | 99.8% | 28.6% |
| Recurrent Transformer (Yang 2023) | 100% | 32.9% |
| ConsFormer (2k iters) | 100% | 65.88% |
| ConsFormer (10k iters) | 100% | 77.74% |
ConsFormer 的设计理念和 2×2 框架完全一致:约束图 RPE(成对交互)+ 迭代 deployment(可迭代)。
6. BDH(Baby Dragon Hatchling):Fast Weights + Hebbian Learning
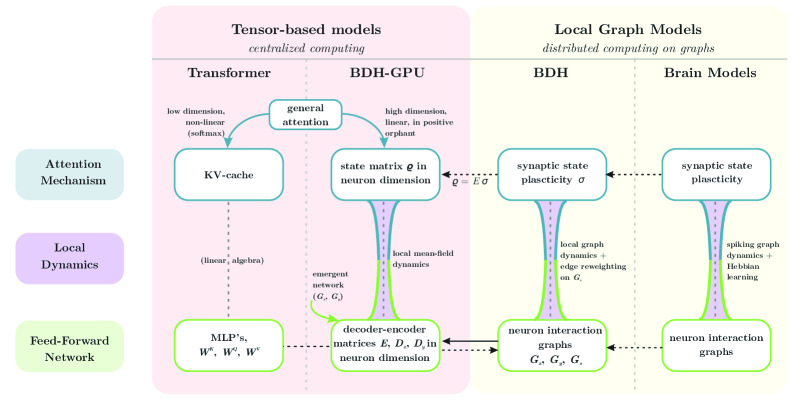
BDH [ref] 将推理建模为 n 个神经元粒子的局部交互,推理状态存储在 O(n²) 的**突触权重(fast weights)**中。推理过程本身通过 Hebbian 规则修改突触权重——“同时激活的 cell 之间加强连接”——这恰好是约束传播的自然描述。
- 成对交互:O(n²) 突触权重直接编码变量对 (i,j) 的关系
- 可迭代:Hebbian update 持续修改突触
实证:97.4% [ref]。
7. HRM(Hierarchical Reasoning Model):分层递归
HRM [ref](Wang et al., 2025)使用两层递归架构(slow planning + fast computation),仅 27M 参数、1000 训练样本。
- 成对交互:每次递归中变量重新交互
- 可迭代:递归不限深度
实证:近乎完美的 Sudoku 准确率 + 大型迷宫最优路径 [ref]。
8. Neural GPU:成对交互 + 可迭代 = 100%
Neural GPU [ref](Kaiser & Sutskever, 2016)使用卷积门控单元在序列上迭代运算。相邻位置的信息交互(卷积核 = 成对交互)+ 多步迭代(可迭代)。
实证:在 Copy、Reverse、Addition 任务上达到 100%(使用 curriculum training [ref])。
汇总:2×2 矩阵
| 无成对交互 | 有成对交互 | |
|---|---|---|
| 不可迭代 | SSM(检索失败 [ref]) | Transformer(Sudoku 0%) |
| 可迭代 | LSTM(cell acc 46.7%,~0% puzzle) | UT ✓ RRN 96.6% ✓ ConsFormer 77.74% OOD ✓ BDH 97.4% ✓ HRM ~perfect ✓ Neural GPU 100% ✓ |
六个右下角架构,机制各异(图消息传递、fast weights、分层递归、卷积门控、共享权重 attention),全部在约束满足上表现优异。它们的共同点不是某个特定机制,而是同时满足了成对变量交互 + 可迭代两个条件。
正交的第三维度:训练范式
即使架构满足两个条件,训练范式仍然可以导致失败。一组关键的对比数据:
| 方法 | 架构 | 训练方式 | 测试时增加迭代 | 结果 |
|---|---|---|---|---|
| Yang 2023 | Recurrent Transformer | 32 步端到端 | 32→2000 步 | 从 32.9% 降到 14% |
| ConsFormer | 迭代 Transformer + 约束图 RPE | 1 步 | 1→10000 步 | 持续上升到 77.74% |
两个架构都满足"成对交互 + 可迭代"。但 Yang 2023 训练 32 步端到端——模型学到了步数特异性行为(“第 5 步做粗略调整,第 30 步做精细调整”),超出训练步数后行为未定义。ConsFormer 训练 1 步——模型学到的是一个关于当前状态的局部改善函数 f:state → better state,不依赖步数。
局部改善器 vs 端到端求解器
这个区别有更深的数学含义。如果局部改善函数 f 近似于一个压缩映射(contraction mapping)——即 ,其中 ——那么根据 Banach 不动点定理,从任何初始状态出发,反复应用 f 都会收敛到唯一的不动点(即满足所有约束的解)。更难的问题只需要更多迭代。
ConsFormer 还有一个关键设计:每步只更新一个随机子集的变量(概率 )。论文的消融实验显示 [ref]:确定性更新()快速收敛但停滞于 20%,随机子集更新更慢但稳定收敛到接近 100%——类似随机坐标下降避免局部最优。

Diffusion 模型天然是局部改善器:每步只做局部去噪,不试图一步到位。这解释了 IRED [ref] 等 diffusion-based CSP solver 的有效性(Sudoku 62.1% OOD)。Geiping et al. (2025) [ref] 直接证明了 recurrent-depth 模型和 diffusion 模型之间的数学联系——两者核心都是迭代细化。
Bansal et al. (2022) [ref] 在研究 recurrent ResNet 的算法外推时独立发现了同样的 overthinking 问题——迭代超过训练步数后性能退化——并提出 progressive training 作为折中方案。
训练范式的统一图景
| 训练范式 | 典型方法 | 测试时增加迭代 | 原理 |
|---|---|---|---|
| 局部改善器(训练 1 步) | ConsFormer, diffusion CSP | 性能持续上升 | 近似压缩映射,收敛到不动点 |
| 端到端求解器(训练 N 步) | Yang 2023 | 性能下降 (overthinking) | 步数特异性行为 |
| Progressive training | Bansal 2022, Neural GPU | 可以外推 | 逐渐增加步数,防止步数特异性 |
与架构条件的正交性:训练范式是独立于架构的第三个维度。一个架构可以满足"成对交互 + 可迭代"但仍然因为训练范式不对而失败(Yang 2023);反过来,正确的训练范式不能补救架构缺陷(没有成对交互的模型即使训练局部改善器也没用,因为单步改善本身就需要成对交互来传播约束)。
与 SSM-Attention 互补的联系
这个 2×2 框架和之前分析的 SSM-Attention 互补性 [ref] 有一个深层联系:
SSM 的检索瓶颈和约束满足瓶颈可能有相同的根源——缺乏状态空间内部的成对交互。SSM(Mamba 等)的状态更新是对角化的(每个状态维度独立演化),和 LSTM 的 Hadamard 乘积一样,维度之间没有直接交互路径。
这形成了一个三角关系:
| 能力 | 需要什么 | 最佳架构 | 为什么 |
|---|---|---|---|
| 信息压缩 | 固定状态 + 递归处理 | SSM | 压缩偏置天然匹配 |
| 精确检索 | 完整历史 + 内容寻址 | Attention (KV cache) | Wen 证明 o(n) memory 不够 |
| 约束满足 | 成对交互 + 可迭代 | BDH, ConsFormer, RRN, UT, … | 本文论证 |
标准 Transformer 有 attention(解决检索)但不可迭代(无法解决约束满足)。当前 Hybrid 架构(SSM + Attention)解决了"记忆"的问题(压缩 + 检索),但可能还没解决"推理/搜索"的问题。
对 LLM 的启示
CoT 是一种迭代推理的尝试,但它有两个限制:
- 不可回溯:每个 token 的生成是 autoregressive 的,无法修改已输出的 token。这与"可迭代"的精神——基于更新后的状态重新传播约束——矛盾。
- 不是局部改善器:CoT 不是"改善当前状态",而是"在文本空间中展开搜索步骤"。区别在于:局部改善器的每一步都在同一个状态空间中操作,CoT 的每一步只能向前追加文本。
这可能是 CoT 在约束满足问题上效果有限的结构性原因——标准 Transformer + CoT 是"有成对交互但用不可回溯的方式尝试迭代",不完全满足第二个条件。
与训练信号的正交性
本文讨论的是架构条件,但推理能力还受训练信号的制约。之前的"约束可执行化"框架 [ref] 论证了外部验证器是推理能力的训练基础,RLVR 的实践进一步验证了这一点:验证器存在的域(数学/代码)推理能力提升巨大,验证器缺失的域基本停滞 [ref]。
架构条件和训练信号是两个独立的瓶颈。O3-mini 在数学竞赛上的成功(有验证器 + 语言先验足够弥补架构限制)和在 Extreme Sudoku 上的失败(有验证器但架构不满足条件),正好说明了这两个瓶颈的独立性。
局限性
1. LSTM 反例的实证强度有限
纯 LSTM 的 Sudoku 数据来自 Stanford CS230 学生项目 [ref],实验设计和超参数调优可能不够充分。框架的更强预测——“即使规模无限大,纯 LSTM 也不能解约束满足”——目前只有间接证据。不过 RRN 的成功(LSTM + 图消息传递 = 96.6%)从另一个方向支撑了论点:关键变量不是 LSTM 本身,而是消息传递机制。
2. 2×2 矩阵可能过度简化
真实的区分可能是一个连续谱:
- 完全没有成对交互(SSM 对角化状态)
- 间接成对交互(LSTM 通过输入矩阵)
- 单次成对交互(标准 Transformer attention per layer)
- 可迭代成对交互(BDH, ConsFormer, UT, RRN, …)
二元分类忽略了中间地带。不过,实证数据表明中间地带的效果确实落在两个极端之间(如 LSTM cell-level 46.7%,不是 0% 也不是 97%),这与"连续谱"的预期一致。
3. Sudoku 是特殊问题
Sudoku 是高耦合、零容错的纯约束满足问题。大多数现实推理任务有更多容错空间、部分解就有价值。“在 Sudoku 上失败"不等于"不能推理”。正如 Reddit 评论者指出:“Humans also can’t solve sudoku without at least external state” [ref]。标准 Transformer + 工具调用(Python SAT solver)可以轻松解决 Sudoku——"能选择正确工具"可能比"原生解决"更实用。
4. BDH 的语言能力未经大规模验证
BDH 在语言建模上只和 GPT-2 comparable(2019 年水平 [ref])。是否能在 GPT-4 级别规模上保持 Sudoku 的优势?Reddit 评论者指出 BDH 本质上是 Linear Attention / Fast Weight Programmer 的变体 [ref]——这类架构在大规模语言建模上一直落后于 full Transformer。约束满足能力和语言建模能力之间是否存在根本性的架构张力?这是一个开放问题。
5. 压缩映射只是一个类比
ConsFormer 的 f 使用 Gumbel-Softmax(离散化),状态空间不连续,Banach 定理的条件可能不完全满足。"近似压缩映射"的直觉可能有效,但需要更严格的分析。ConsFormer 训练 2 步或 5 步的效果如何?是否存在最优训练步数?论文未报告。
总结
约束满足需要两个正交的架构条件:
- 成对变量交互:变量 i 和变量 j 之间需要直接的信息通道,使约束能在变量对之间传播
- 可迭代执行:这种传播需要能反复执行,每次基于更新后的状态
八个架构的实证数据系统验证了这个框架:缺少任何一个条件都会导致约束满足失败(LSTM 缺成对交互 → 46.7%/0%;Transformer 缺迭代 → 0%),两个条件都满足则成功(UT、RRN、ConsFormer、BDH、HRM、Neural GPU)。
训练范式是与架构正交的第三个维度:即使架构满足两个条件,端到端训练 N 步仍可能导致 overthinking(Yang 2023);训练为局部改善器(1 步训练,近似压缩映射)则允许无限迭代。
这个框架的最大实用价值在于:它预测了标准 Transformer(包括 CoT)在紧耦合约束满足上有结构性限制——不是通过更多数据或更大模型能解决的。对于需要这类推理的应用,架构级别的改变(引入可迭代的成对交互机制)可能是必要的。
关键引用
- Xu et al. (2025). Self-Supervised Transformers as Iterative Solution Improvers for Constraint Satisfaction. ICML. [ref]
- Palm et al. (2018). Recurrent Relational Networks. NeurIPS. [ref]
- Wang et al. (2025). Hierarchical Reasoning Model. [ref]
- Kosowski et al. (2025). The Dragon Hatchling: The Missing Link between the Transformer and Models of the Brain. [ref]
- Dehghani et al. (2019). Universal Transformers. [ref]
- Kaiser & Sutskever (2016). Neural GPUs Learn Algorithms. [ref]
- Yang et al. (2023). Learning to Solve Constraint Satisfaction Problems with Recurrent Transformer. ICLR. [ref]
- Bansal et al. (2022). End-to-end Algorithm Synthesis with Recurrent Networks: Extrapolation without Overthinking. NeurIPS. [ref]
- Du et al. (2024). Learning Iterative Reasoning through Energy Diffusion. ICML. [ref]
- Geiping et al. (2025). Efficient Parallel Samplers for Recurrent-Depth Models and Their Connection to Diffusion Language Models. [ref]
- Wen, Dang, Lyu (2024). RNNs are not Transformers (Yet): The Key Bottleneck on In-context Retrieval. [ref]
- Akin-David (2018). Sudoku Solver using LSTM. Stanford CS230. [ref]
- Pathway Blog: Beyond Transformers Sudoku Bench. [ref]
- Reddit 讨论帖. [ref]
- SSM 与 Attention 的信息论互补. [ref]
最后更新: 2026-03-22 07:50
更新内容: 添加 Universal Transformer 和 BDH 架构图