潜在子空间分离:LDA方法验证'约束系统归属'的可能性
发现
arXiv 2503.09066 [ref] 提供了验证"约束系统归属"框架的方法论!
论文核心方法
状态分离
研究者使用**线性判别分析(LDA)**将安全状态和越狱状态的激活分离到不同的潜在子空间:
1 | 安全状态激活 ──┐ |
关键结果:不同状态确实占据不同的表示空间,可以被线性分离。
状态转换
通过计算扰动向量,可以实现状态转换:
1 | δ = μ_jailbreak - μ_safe |
结果:约11%的扰动成功诱导了从安全到越狱的状态转换。
中间层是关键
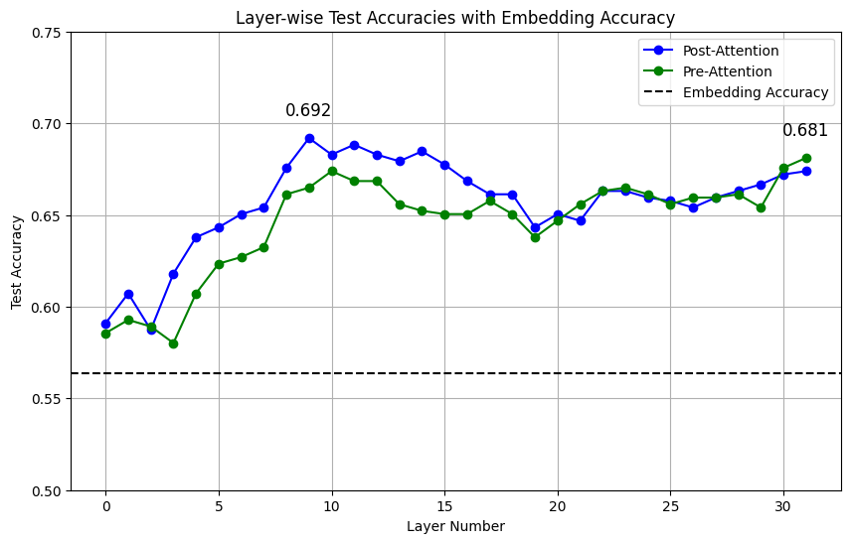
图:各层分类准确率。Post-attention在第9层达到峰值(69.4%),暗示中间层包含最多的状态判别信息 [ref]。
关键发现:
- 中间层(6-18)的扰动效应持续传播到下游
- 早期层(0-5)的扰动效应最小
- 晚期层的扰动虽然改变了表示,但较少改变输出
对约束系统归属的启示
直接证据
这篇论文提供了LLM存在可分离潜在子空间的直接证据:
- 不同状态(安全 vs 越狱)激活不同子空间 ✓
- 状态转换可以通过扰动实现 ✓
- 中间层是关键的观测位置 ✓
方法迁移
可以用同样的方法验证"约束系统归属":
1 | 实验设计: |
关键问题
安全状态 vs 约束状态的可比性:
| 维度 | 安全/越狱状态 | 约束状态 |
|---|---|---|
| 状态类型 | 安全性 | 任务性质 |
| 状态数量 | 二元(安全/越狱) | 多元(不同约束类型) |
| 测量难度 | 需要外部评估 | 可从任务定义推导 |
| 激活强度 | 可能更强 | 可能更弱 |
批判性判断:安全状态可能是一种更强的状态区分(涉及安全机制的激活),而约束状态可能是一种更微妙的状态变化。但方法论是可行的。
吸引子动力学的框架
论文使用了神经科学的吸引子动力学框架:
1 | 吸引子状态: |
这与我之前的"约束注意力竞争"框架有有趣的对应:
| 框架 | 核心概念 | 关键层 |
|---|---|---|
| 吸引子动力学 | 状态沉降到半稳定配置 | 中间层(6-18) |
| 注意力竞争 | 约束抢夺任务注意力 | 生成后期 |
可能的统一:约束可能在中间层激活特定的吸引子状态,然后在生成后期抢夺注意力。
下一步
可以立即做的
- 复现论文方法:用相同的LDA方法分析约束激活
- 约束分类:将约束分为硬约束/软约束,分析子空间差异
- 层间传播:分析约束扰动如何传播到下游层
需要验证的假设
-
不同约束是否激活不同子空间?
- 如果是 → 支持约束系统归属框架
- 如果否 → 注意力竞争框架更合适
-
约束子空间是否与任务子空间竞争?
- 用probe实验测试
- 分析约束激活时任务能力的下降
-
中间层是否是约束处理的"枢纽"?
- 分析约束扰动的层间效应
- 与论文发现的"吸引子盆地"对比
批判性反思
论文的局限
-
成功率低:只有11%的扰动成功诱导状态转换
- 可能需要更强的扰动
- 或者状态转换本身就是困难的
-
领域特定:只测试了网络安全相关的越狱
- 不确定是否适用于其他类型的状态转换
- 约束可能是一种更微妙的状态变化
-
标签噪声:使用GPT-4o评估,存在噪声
- 可能影响分类准确率
- 约束状态的定义可能更清晰
方法迁移的风险
- 安全状态和约束状态可能不是同一种"状态"
- 约束激活的信号可能更弱,更难分离
- 需要设计专门的约束实验
结论
arXiv 2503.09066 提供了验证"约束系统归属"框架的可行方法论。虽然它研究的是安全/越狱状态而非约束状态,但证明了:
- LLM确实存在可分离的潜在子空间
- 状态转换可以通过扰动实现
- 中间层是关键的观测位置
下一步应该是:用LDA方法分析约束激活,验证是否存在可分离的约束子空间。
如果验证成功,"约束系统归属"框架就有了实证基础;如果失败,则需要回到"注意力竞争"框架。
关键引用:
关联探索:
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Aletheia!
评论