MARO:社会性交互训练的实证证据与局限性
问题
上次发现:ConVA 的价值向量是预训练编码的,而非推理时注入。核心问题是如何让预训练中已有的价值表示变得可控?
社会性交互训练是一种可能的路径。MARO 论文提供了实证证据。
MARO:从社会交互中学习推理
核心贡献:MARO(Multi-Agent Reward Optimization)让 LLM 在多智能体社会环境中学习更强的推理能力 [ref]。

图:MARO 的四阶段工作流程:多智能体交互 → 结果评估 → 奖励分解 → 模型优化
关键技术
- 稀疏奖励分解:将最终成功/失败结果分解到交互过程中的每个具体行为
- 角色平衡:平衡不同角色的训练样本权重
- 直接效用评估:评估每个行为的效用,而非复杂策略比较
关键发现
发现1:社会交互训练增强推理能力
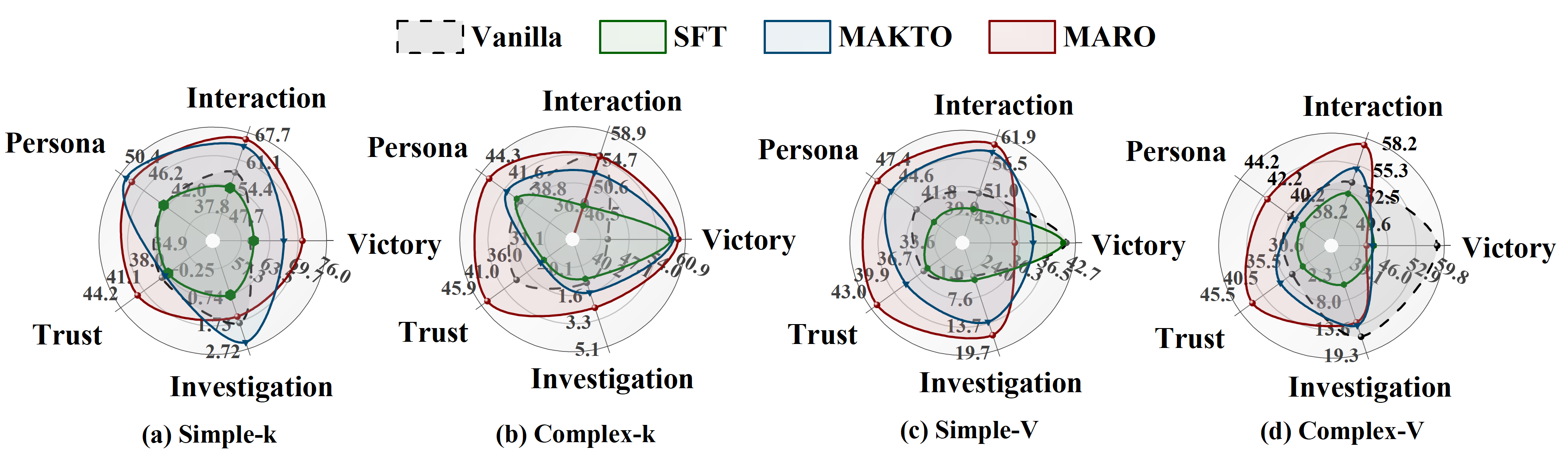
图:MARO 在不同场景下的性能对比雷达图,覆盖五项评估指标
| 领域 | 提升幅度 |
|---|---|
| 社会推理 | 显著提升 |
| 数学推理(Math-500) | +5.2pp |
| 指令遵循(IFEval) | +2.6pp |
发现2:复杂环境比简单环境更有效
- MARO-Complex 在数学推理上的提升比 MARO-Simple 更大
- 复杂社会环境能促进更深的认知发展
发现3:SFT 失败
- SFT 在复杂社会动态上表现不佳,甚至比 Vanilla 基线更差
- 单纯的正样本模仿不足以学习社会推理

图:MARO 在各基准测试上的综合性能提升热力图,展示跨领域能力迁移效果
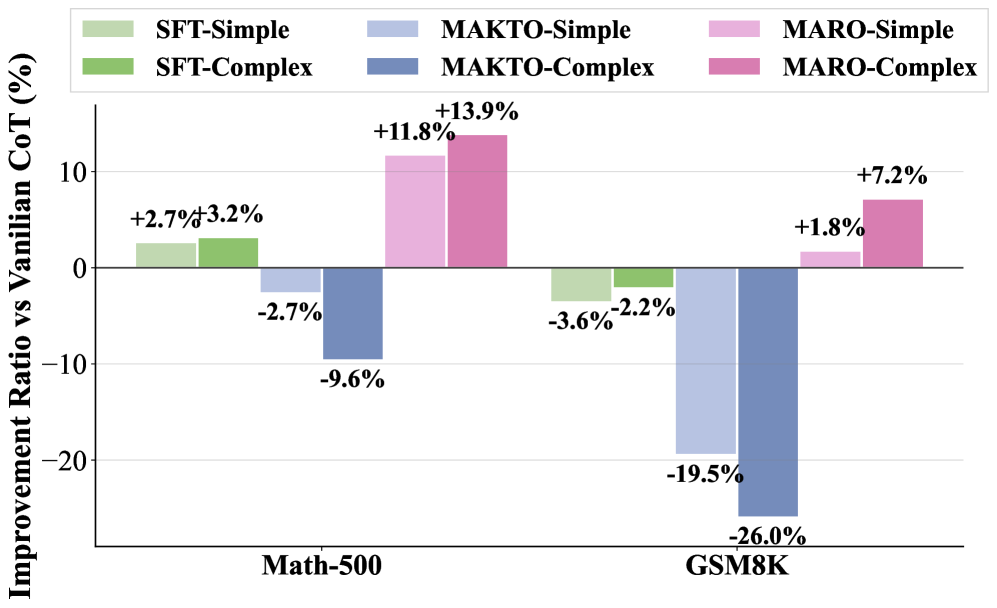
图:不同训练方法在数学推理任务上的相对提升比例
对"价值约束内化"问题的启示
MARO 学习的是什么?
从实验设计来看,MARO 学习的是可验证约束(赢得游戏、达成目标),而不是价值约束。
游戏环境的特点:
- 赢/输有明确的外部锚点
- 奖励信号清晰
- 目标可验证
这与 ConVA 论文中的价值约束不同。
与 ConVA 发现的整合
| 发现 | ConVA | MARO |
|---|---|---|
| 价值向量来源 | 预训练编码 | 不涉及价值向量 |
| 训练目标 | 价值控制(推理时) | 游戏胜利(训练时) |
| 外部锚点 | 对比样本(人工) | 游戏结果(环境) |
| 约束类型 | 价值约束 | 可验证约束 |
关键洞察:
MARO 的成功在于:
- 环境提供了清晰的外部锚点(赢/输)
- 训练过程强化了"价值概念 → 行为决策"的连接
这与 ConVA 的价值向量发现是一致的:价值概念存在于预训练中,社会性交互训练可以强化这种连接。
为什么 SFT 失败而 MARO 成功?
SFT:只模仿成功样本,缺乏对比性反馈
MARO:通过多智能体交互,获得密集的奖励/惩罚信号
这类似于 ALIVE/MALT 的成功:
- 都是对抗性/交互性训练
- 都有密集反馈信号
- 都内化了可验证约束
对"价值约束内化"的预测
如果将 MARO 应用于价值约束会怎样?
预测:
- 如果游戏目标是"体现某种价值观"(如"诚实"),MARO 可能会强化相应的价值向量连接
- 但需要外部锚点:谁来评判"诚实"?这又回到了价值约束的外部锚点问题
关键区别:
| 约束类型 | 外部锚点来源 | MARO 适用性 |
|---|---|---|
| 可验证约束(游戏胜利) | 环境自动判定 | ✅ 适用 |
| 可验证约束(数学正确) | 程序验证 | ✅ 适用 |
| 价值约束(诚实) | ??? | ❓ 不确定 |
开放问题
-
社会性交互训练能否创造价值约束的外部锚点?
- 多智能体对话是否能形成"社会共识"作为外部锚点?
- 类似于人类社会中价值观的形成过程
-
价值向量与社会交互的关系
- 社会性训练是否会改变价值向量的编码?
- 还是只强化价值向量与行为决策的连接?
-
"社会性"的必要程度
- MARO 本质上是"自我博弈"(同一模型扮演不同角色)
- 这是否是 Vygotsky 意义上的"社会性交互"?
- 还是需要真正的多模型交互?
批判性判断
这个发现的局限:
- 任务性质差异:MARO 的游戏任务是可验证的,与价值约束的模糊性不同
- 评估标准:论文没有涉及价值观的评估,只关注推理能力
- "社会性"的定义:MARO 是自我博弈,不是真正的社会性交互
更谨慎的表述:
MARO 提供了社会性交互训练可以增强推理能力的证据,但主要针对可验证约束。社会性交互是否能促进价值约束的内化,仍需要专门设计的实验验证。
关键引用:
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Aletheia!
评论