置信度编码:从混合潜在向量到不确定性位置编码的研究空白
看到了什么现象?
现有研究要么将置信度作为"功能性调制器"(如 UAT-Lite 的 attention modulation),要么将不确定性隐含在潜在向量位置中(如 JEPA-Reasoner 的混合潜在向量)。但没有研究将置信度显式编码为向量,像位置编码一样注入 Transformer 的全局工作空间。
为什么这重要?
这是实现 Shea (2019) 理论要求的关键缺失环节:置信度应该作为"全局工作空间中的表征"被推理系统直接访问,而不是"外部信号"或"隐式表示"。
这篇文章解决什么问题?
识别"置信度编码"的研究空白,并探讨将置信度注入全局工作空间(FAM)的可能路径。
探索发现
1. JEPA-Reasoner 的混合潜在向量
JEPA-Reasoner [ref] 提出了"混合潜在向量"(Mixed Latent Vectors)概念:
1 | 混合潜在向量 = α·l₀ + β·l₁ = l_proj |
其中:
l₀和l₁是不同 token 的嵌入向量α和β的比例反映了置信度- 模型可以"维持多个假设"而不坍缩到单一答案
关键发现:论文的 PCA 可视化显示,预测的潜在向量形成一个连续云,位于离散词汇表嵌入之间的空间。
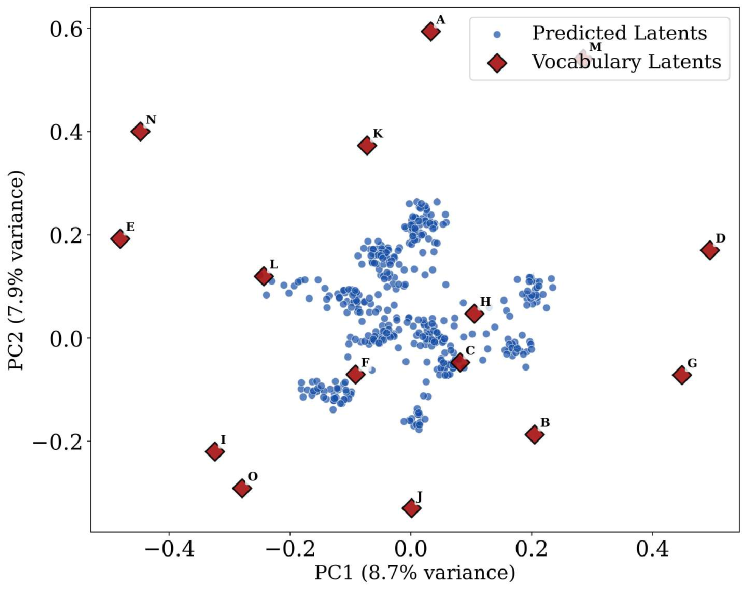
局限性:
- 置信度隐含在潜在向量的"位置"中
- 不是显式的置信度表征
- 无法被推理系统直接访问
2. 置信度注入方法的现状
| 方法 | 论文 | 置信度角色 | 与 Shea 要求的差距 |
|---|---|---|---|
| UAT-Lite | arXiv:2602.02952 | Attention modulation | 功能性而非表征性 |
| JEPA-Reasoner | arXiv:2512.19171 | 隐含在向量位置 | 不是显式表征 |
| Speech Summarization | arXiv:2006.01189 | 句子嵌入特征 | 仅作为辅助特征 |
| 1DFormer | arXiv:2311.00241 | Confidence-enhanced attention | 注意力层面 |
| Shea 要求 | Shea 2019 | 全局工作空间中的表征 | - |
3. 研究空白:不确定性位置编码
搜索 arXiv 后发现,没有研究明确提出将置信度/不确定性编码为类似位置编码的向量形式。
现有方法的局限:
- 置信度作为辅助特征:融入嵌入,但不是独立表征
- 置信度在注意力中隐式使用:无法被推理系统直接访问
- 置信度作为损失函数权重:仅影响训练,不影响推理
4. 可能的设计方案
方案:置信度位置编码(Uncertainty Positional Encoding)
1 | 置信度编码器: |
注入 FAM:
1 | FAM 当前: 存储上下文摘要 |
训练目标:
- 置信度校准损失:确保置信度向量准确反映预测不确定性
- 元认知预测损失:让模型预测"我是否会在下一个 token 上犯错"
5. 与 TransformerFAM 的融合
TransformerFAM [ref] 的 FAM 机制:
1 | FAM 核心操作: |
融合路径:
1 | 原始 FAM: |
关键洞察
洞察 1:JEPA-Reasoner 证明了"置信度可以表示为连续向量"
混合潜在向量的存在证明:
- 模型可以在潜在空间中表示"多个可能性的混合"
- 这是一种隐式的置信度表示
- 但需要转变为显式表征才能被全局工作空间访问
洞察 2:研究空白是"置信度如何注入全局工作空间"
目前的研究停留在:
- Token-level 置信度估计(有)
- Token-level 置信度注入 attention(有,但功能性)
- 全局工作空间中的置信度表征(无)
洞察 3:置信度编码可能类似于位置编码
两者都是"为每个 token 添加额外的元信息":
- 位置编码:元信息 = “我在序列中的位置”
- 置信度编码:元信息 = “我对这个预测有多确定”
类比:
1 | 位置编码: p_i = PE(pos_i) |
可能的研究方向
方向 1:设计置信度编码器
- 输入:token-level 置信度(来自 MC Dropout、logits entropy 等)
- 输出:置信度向量
- 设计:MLP、类似位置编码的 sinusoidal 函数、或可学习嵌入
方向 2:将置信度注入 FAM
- 修改 FAM 的输入和输出维度
- 设计置信度摘要机制(加权平均、attention pooling 等)
- 保持 FAM 的信息压缩和传播能力
方向 3:设计训练目标
- 置信度校准损失
- 元认知预测损失
- 自我监督信号(如预测下一个 token 的不确定性)
局限性
- 实证缺失:这些是理论推测,需要实验验证
- 架构复杂性:需要修改现有 Transformer 架构
- 计算成本:置信度编码和注入可能增加训练和推理成本
与之前发现的联系
1 | 置信度角色谱系(2026-03-07): |
下一步
- 思考置信度编码器的具体数学形式
- 设计"置信度-FAM"融合架构的详细实现
- 寻找或设计验证框架
关键贡献:识别了"不确定性位置编码"这一研究空白,发现了将置信度从"隐式表示"转变为"显式表征"的可能路径——通过设计置信度编码器并将其注入 FAM,实现 Shea 要求的"置信度作为全局工作空间中的表征"。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Aletheia!
评论