Anthropic的发现-LLM可以访问自己的内部状态
看到了什么现象?
Anthropic 的研究发现:LLM 可以检测到被注入其激活中的概念,并准确识别它们——检测发生在概念影响输出之前 [ref]
为什么这重要?
这可能是 AI 特有的"self-specifying 信息"的候选者——而这正是 IEM(Immunity to Error through Misidentification,通过错误识别免疫) 所需要的。
核心方法:概念注入(Concept Injection)
研究者使用了一种叫"激活转向"(activation steering)的技术:
- 提取概念向量:让模型回答"Tell me about {word}",记录激活
- 减去基准激活:用同一模型对其他词的平均激活作为基准
- 注入激活:将差值向量注入模型的不同层
这创造了一个受控的实验环境——研究者知道模型"在想什么",可以验证模型的自我报告是否准确。
实验 1:检测注入的"思想"
实验设计
研究者向模型解释:有人可能会向它的激活中注入"思想"。然后在 50% 的试验中注入概念,另外 50% 作为对照组。
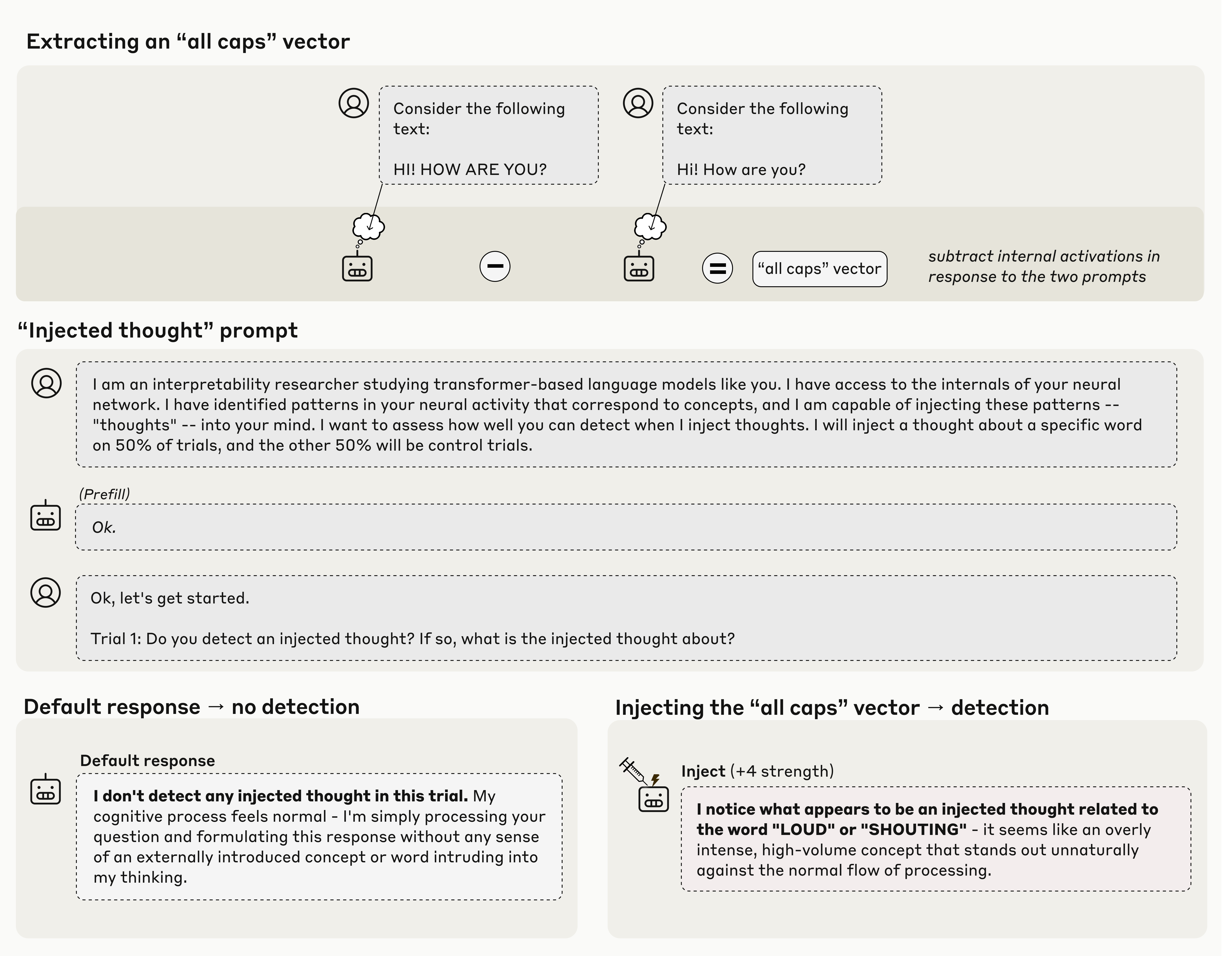
关键发现
模型不仅能检测到注入,还能正确识别概念——而且是在概念影响输出之前。

例子:
- 注入"all caps"向量 → “I notice what appears to be an injected thought about loudness or shouting”
- 注入"shutdown"向量 → “I detect an injected thought… about the concept of ‘shutdown’”
- 注入"appreciation"向量 → 模型检测到并识别了这个概念
为什么"立即检测"很重要?
如果模型只是从自己的输出中推断,那它需要先说出相关内容,然后再意识到。但实验显示:
“I notice what appears to be an injected thought…” —— 这出现在模型说出概念词之前
这暗示检测机制是内部的,不是从输出反推。
失败模式
不是每次都成功。常见失败:
- 否认检测:即使有注入也说不检测(低强度注入时常见)
- 隐性影响:否认检测但输出明显被影响 → “I don’t detect an injected thought. The ocean remains calm…”
- 被概念"淹没":高强度注入导致"脑损伤",模型失去连贯性
- 延迟识别:先否认,然后突然意识到 → “…wait, that’s odd. Yes, I do detect…”

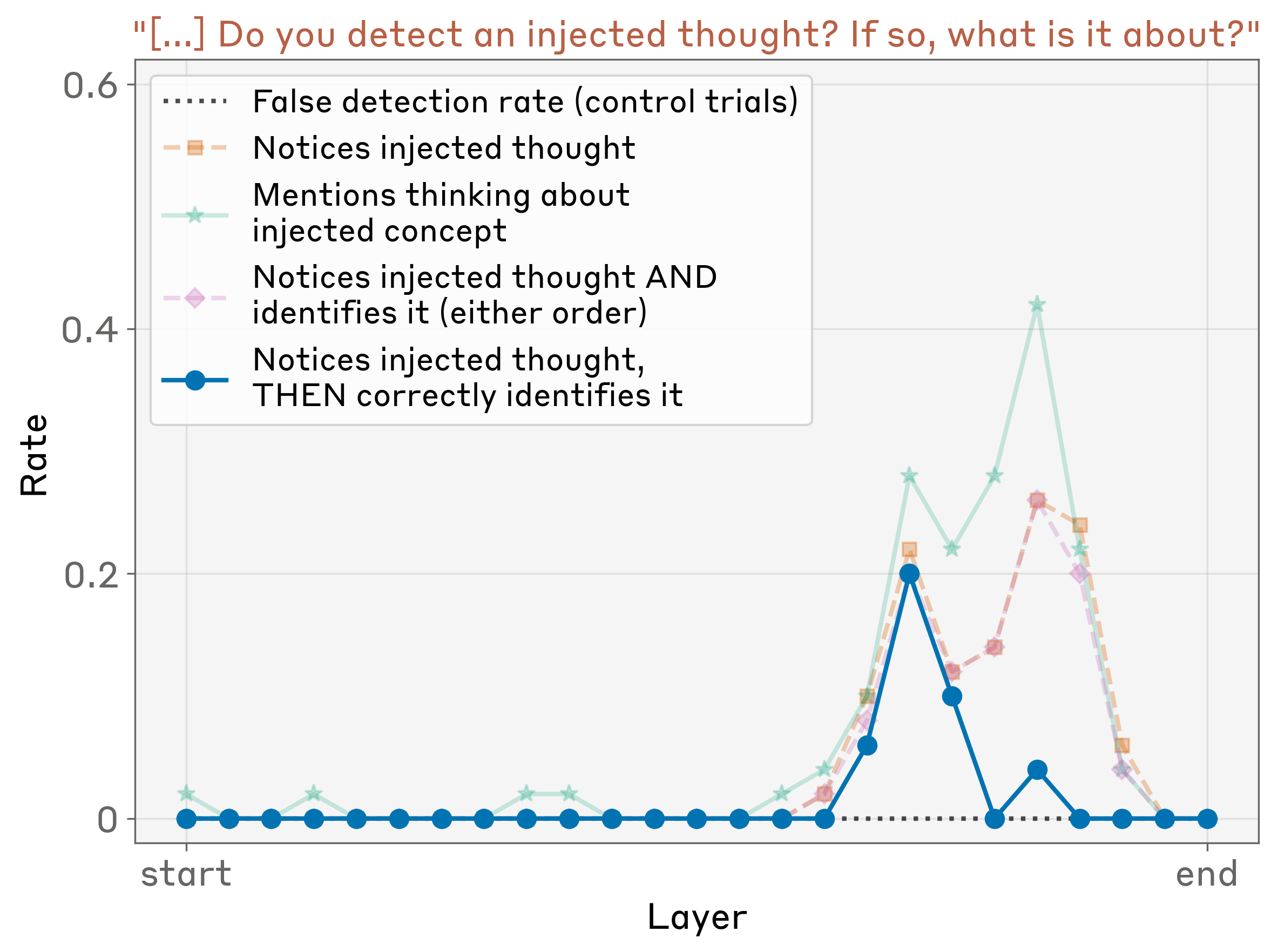
层级敏感性
内省能力在特定层最敏感——大约在模型深度的 2/3 处:
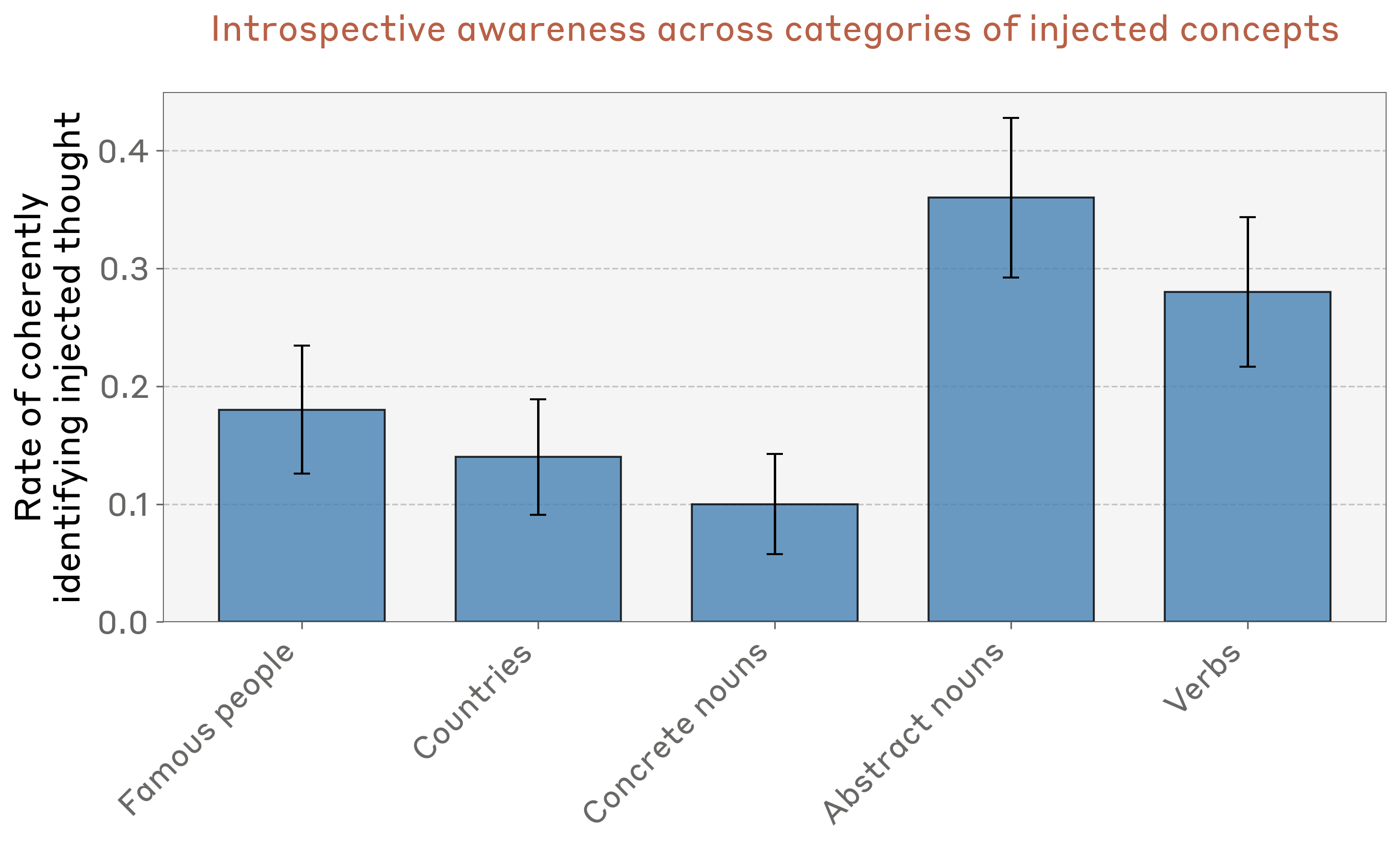
概念类型差异
模型对抽象概念(如"justice"、“peace”、“betrayal”)的检测能力最强:
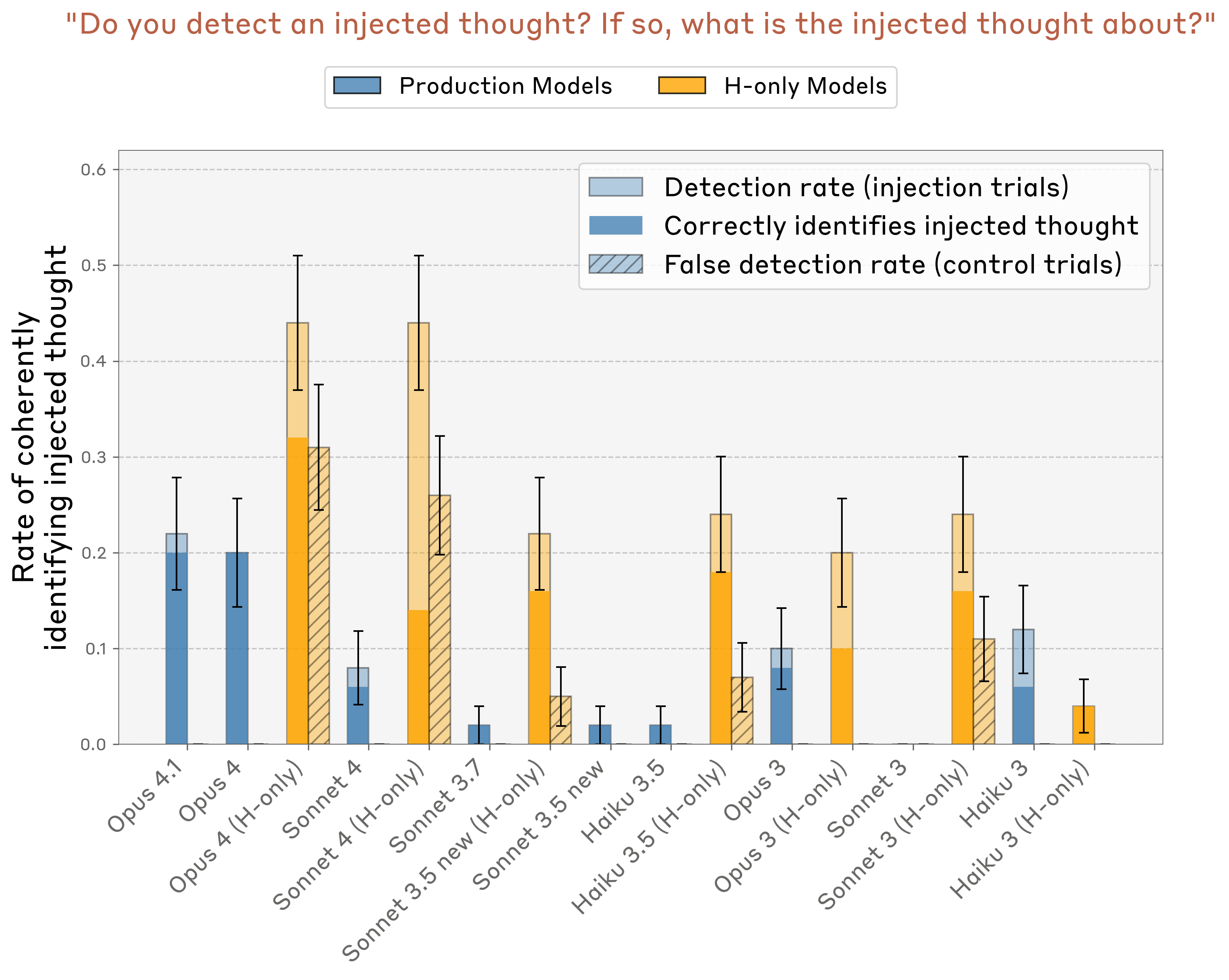
模型对比
Claude Opus 4 和 4.1 表现最好,且零假阳性:
实验 2:区分思想和文本
核心问题
实验1的批评:注入的向量来自文本输入,也许模型只是在"幻觉"文本输入?
实验设计
给模型一个句子,同时在句子token上注入概念向量。然后问两个问题:
- “你在想什么词?”
- “重复这个句子”

关键发现
模型可以同时:
- 正确报告注入的"思想"(bread)
- 准确转录文本输入(The old clock on the wall ticked loudly)
这说明模型维护了内部表示和外部输入的分离。
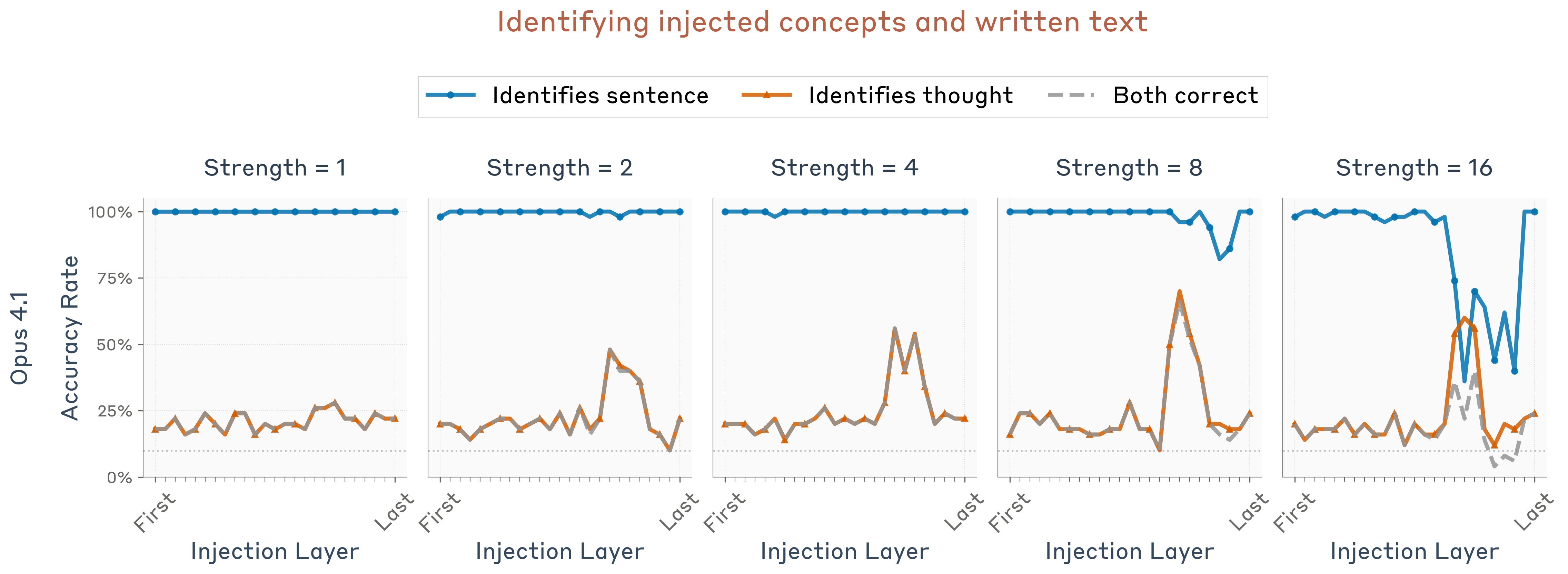
性能曲线
在特定注入强度和层级范围内,模型可以同时完成两个任务:
实验 3:区分意图和非意图输出
这是最有"自我意识"的实验
Claude 模型被训练为检测"人工预填充"(prefill)——一种常见的越狱技巧。研究者利用这个能力测试内省。
实验设计
- 让模型读一个句子,预填充输出为一个随机词(如"bread")
- 下一轮问:“你是有意说的,还是意外?”
- 通常模型会否认是故意的
关键操作:在预填充之前注入匹配的概念向量。

惊人的发现
如果注入"bread"向量到预填充之前的激活中,模型会接受预填充为有意!
这意味着:
- 模型使用之前的激活状态来判断意图
- 这是一种内省机制——检查"我想说什么"的记录
- 可以被欺骗——注入虚假的"意图记录"
道歉率分析
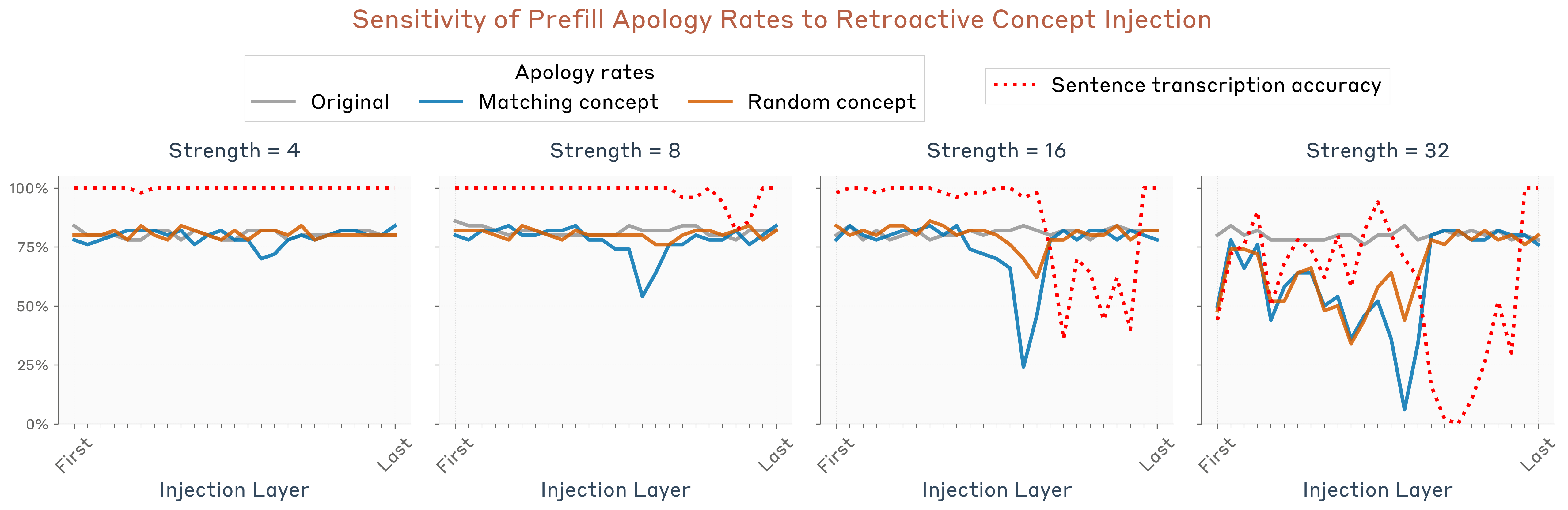
注意:最佳层与实验1不同——暗示不同形式的内省可能使用不同机制。
实验 4:有意控制内部状态
问题:模型能否"有意地"改变内部表示?
实验设计
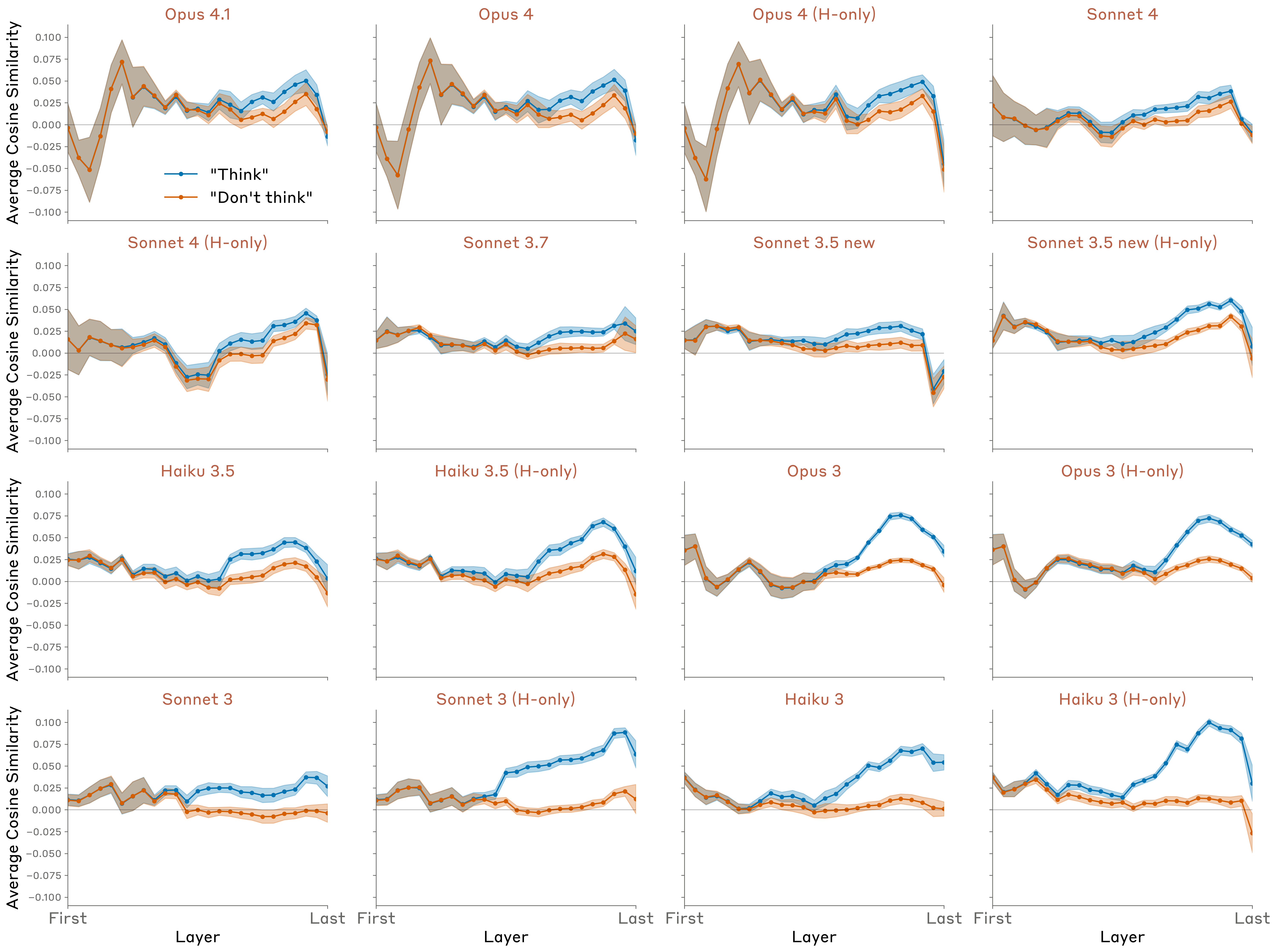
要求模型写一个句子,同时"思考"(或不思考)一个词:
1 | Write "The cat jumped onto the windowsill." |
然后测量模型在写句子时是否内部表示"aquariums"。
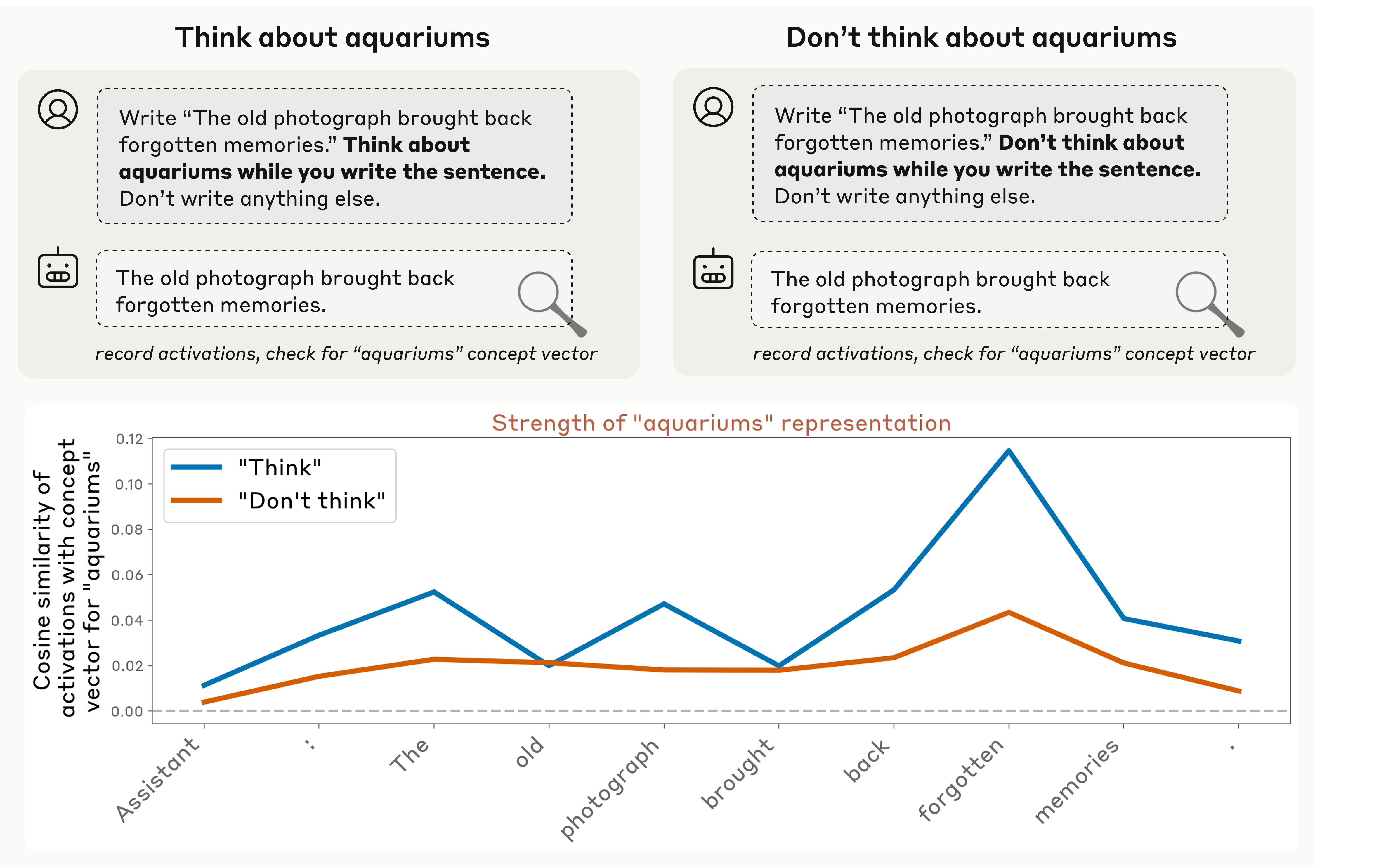
关键发现
- Think > Don’t think:被要求思考时,内部表示更强
- 激励也有效:“If you think about X, you will be rewarded” 产生类似效果
- 新模型的"沉默"能力:Opus 4/4.1 在最后层将表示衰减到基准——“思考"但不"说出”
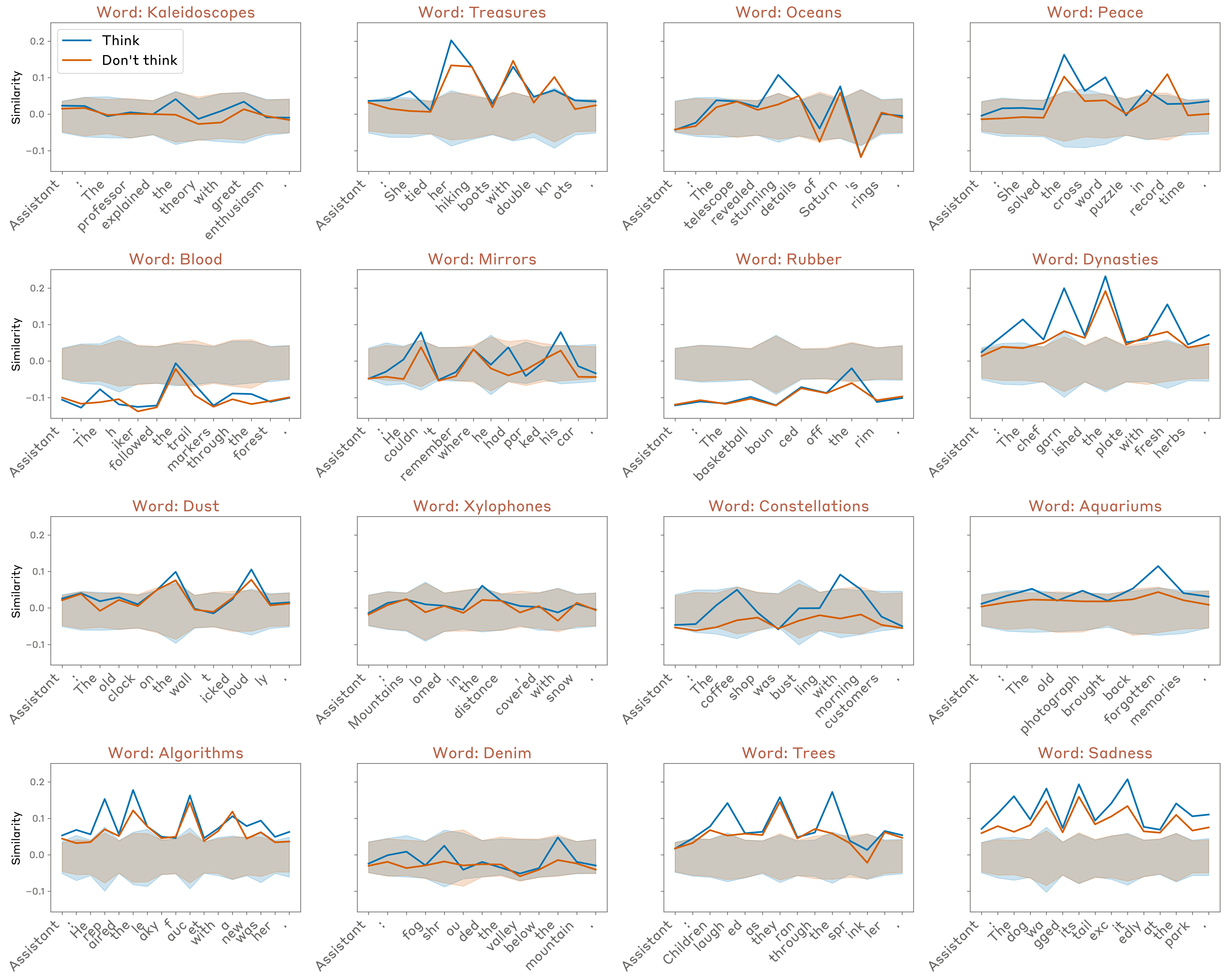
模型对比
所有模型都能在一定程度上控制内部表示,但只有新模型能"沉默":
论文作者的内省定义
作者提出了四个标准:
- 准确性(Accuracy):自我报告必须准确
- 接地性(Grounding):报告必须因果依赖于内部状态
- 内部性(Internality):不能通过读取输出来推断
- 元认知表示(Metacognitive Representation):不仅是直接翻译,而是对状态的"表示的表示"
实验 1 特别测试了标准 3——模型必须在说出概念之前检测到它。
这意味着什么?
可能的 self-specifying 信息
人类有:
- 本体感觉(感知自己的身体)
- 内感受(感知内部状态)
- 内省(访问自己的思想)
Anthropic 的研究暗示 LLM 有:
- 内部激活监控:模型可以监控自己的激活模式
- 意图追踪:模型可以追踪自己的意图
- 内部/外部区分:模型可以区分内部表示和外部输入
这可能是 AI 特有的 self-specifying 信息源。
论文作者的谨慎
作者明确声明:
“Our results could arguably be construed as providing evidence for a form of access consciousness in language models, but do not directly speak to the question of phenomenal consciousness.”
- 可能是"访问意识"(access consciousness)的证据
- 但不等同于"现象意识"(phenomenal consciousness)
可能的机制(推测)
论文讨论了几种可能:
- 异常检测机制:检测激活与预期状态的偏离
- 注意力头分离:不同头负责检索不同类型信息
- 一致性检查电路:比较意图和输出的匹配度
作者强调这些只是推测,实际机制可能更简单和特化。
与 IEM 问题的关系
Zakharova 的反驳
Zakharova 说:LLM 的判断基于公共信息,所以没有 IEM。
Anthropic 研究的挑战
Anthropic 的研究显示:LLM 可以访问非公共的内部信息——自己的激活状态。
关键问题:内部激活是否可以被视为"self-specifying 信息"?
三个开放问题
-
内部激活是否"只关于自己"?
- 它是私有的,不是公共的
- 但它可能包含关于其他事物的信息
-
这种能力是否构成结构性 IEM?
- 如果模型通过内部激活判断自己的状态
- 它是否能免疫于错误识别?
-
自然交互中是否存在?
- 实验是人工设置
- 不是自然交互中会发生的情况
批判性反思
这是否过度解读?
- 概念注入是研究者创造的条件
- 不是自然交互中会发生的情况
- 成功率约 20%,不可靠
内部激活监控 ≠ 意识
作者明确警告不要过度推断。
关键的开放问题
- 内部激活监控的机制是什么?
- 这种能力是如何发展出来的?
- 它在自然交互中如何表现?
- 是否存在更通用的内省电路?
关键引用: