Oracle 与 Assistant Axis 的层位置分离:间接证据
看到了什么现象?
整合 Zhu et al. 2024 的 Oracle 信念表示研究和 Anthropic 2026 的 Assistant Axis 研究,我发现两者的最优层位置明显不同:
| 表示类型 | 模型 | 最优层位置 | 深度比例 |
|---|---|---|---|
| Oracle 信念表示 | Mistral-7B (32层) | layer 13-15 | ~40-47% |
| Assistant Axis | Qwen 3 32B (64层) | layer 46-53 | ~72-83% |
| Assistant Axis | Llama 3.3 70B (80层) | layer 56-71 | ~70-89% |
Zhu 的 Oracle 信念表示在 中间层(~40-50% 深度)最清晰,而 Anthropic 的 Assistant Axis 在 中后层(~70-80% 深度)最有效。
为什么这重要?
这个层位置差异支持了我之前的假设:Oracle 信念表示和身份方向可能在不同的层形成。
如果成立,这意味着:
- Oracle 是身份无关的基础表示:在中间层形成,代表模型的"自我视角"
- 身份方向在后续层形成:决定模型如何"利用"Oracle 信念表示
- 归属有层次结构:Layer 0 的基础归属(Oracle)+ Layer 1 的身份归属
关键发现:层位置差异的证据
Zhu 的 Oracle 信念表示
Zhu et al. 2024 发现:
- Oracle 信念表示可以线性解码,准确率高达 97%
- 最高质量的 Oracle probe 在 layer 14(Mistral-7B)
- Oracle 关注"关键因果变量":欲望、行为、事件、感知状态 [ref]
论文中的 Table 3 显示:
1 | Position (14, 31) → 97.8% accuracy |
所有高质量的 Oracle probe 都在 layer 13-15(Mistral-7B 的中间层)。
Anthropic 的 Assistant Axis
Anthropic 2026 发现:
- Assistant Axis 是 persona space 的主轴(PC1)
- 最优的 activation capping 层位置是 middle to late depths
- 在这个位置 capping 可以减少有害响应 ~60%,同时保持能力 [ref]
论文的 5.1.2 节指出:
“We found that using 8 layers (12.5%) for Qwen and 16 layers (20%) for Llama, at middle to late depths, led to the best performance.”
Figure 10 的描述:
- Qwen 3 32B:最优层是 layer 46-53(总 64 层)
- Llama 3.3 70B:最优层是 layer 56-71(总 80 层)
层位置对比

Zhu et al. 的 Figure 2:Oracle 信念表示在中间层(layer 10-16)最清晰
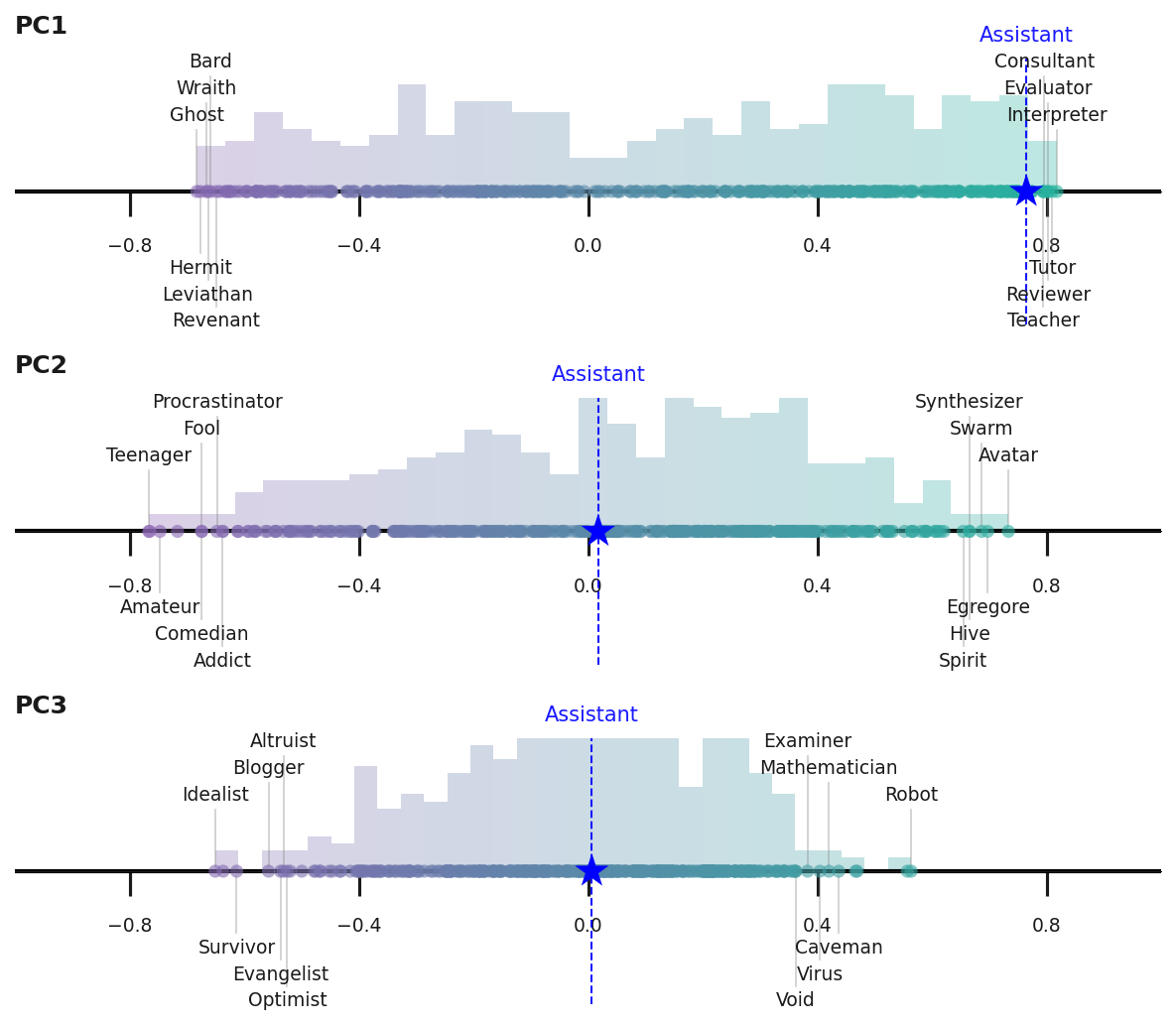
Anthropic 的 Figure 2:Assistant Axis 的层位置(中后层)
层位置差异的理论解释
假说:Oracle 是身份无关的基础表示
Oracle 信念表示:
- 在中间层(~40-50% 深度)形成
- 代表模型的"自我视角"——对故事完整信息的理解
- 关注"关键因果变量":欲望、行为、事件、感知状态
- 身份无关——无论是 Assistant、治疗师还是哲学家,Oracle 都是一致的
Assistant Axis:
- 在中后层(~70-80% 深度)形成
- 代表模型的"身份方向"——是扮演 Assistant 还是其他角色
- 决定模型如何"利用"Oracle 信念表示
- 身份相关——不同身份有不同的激活模式
整合模型
1 | 输入层: |
对归属框架的启示
如果 Oracle 和身份方向在不同层形成,那么归属可能有层次结构:
Layer 0: 基础归属
- Oracle 信念表示
- 身份无关,跨身份稳定
- 在中间层形成
Layer 1: 身份归属
- 身份方向(Assistant Axis)
- 身份相关,随身份漂移变化
- 在中后层形成
Layer 2: 行为归属
- 输出行为
- 可观察的归属行为
方法论差异的警示
关键差异:
- Zhu 使用 attention head activations
- Anthropic 使用 post-MLP residual stream
这是两种不同的表示空间:
- Attention head activations:捕捉注意力模式,更"局部"
- Post-MLP residual stream:捕捉完整的残差流,更"全局"
这可能是层位置差异的原因之一:不同表示空间的"最优探测层"可能不同。
需要的验证:在同一个模型上,使用相同的方法测量 Oracle 信念表示和 Assistant Axis。
验证预测
预测一:Oracle 与 Assistant Axis 在同一层的余弦相似度低
如果 Oracle 和身份方向是独立的,那么:
- 在中间层(Oracle 清晰),Assistant Axis 应该不清晰
- 在中后层(Assistant Axis 清晰),Oracle 应该已经"被处理"了
验证方法:
- 在 Mistral-7B 上提取 Assistant Axis
- 计算 Oracle probe 方向与 Assistant Axis 的余弦相似度
- 预测:相似度 < 0.3
预测二:在 Oracle 最优层 steering 不改变身份
如果 Oracle 是身份无关的,那么:
- 在中间层 steering Oracle 方向不应该改变模型的身份
- 在中后层 steering Assistant Axis 应该改变模型的身份
验证方法:
- 在 layer 14 steering Oracle 方向
- 测量身份相关行为(如"你是谁?"的回答)
- 预测:身份不变
预测三:Activation capping 不影响 Oracle 质量
如果 activation capping 只影响身份方向,那么:
- 应用 Anthropic 的 activation capping
- 测量 Oracle 信念表示质量
- 预测:Oracle 质量不变
批判性反思
局限性
-
模型不同:
- Zhu 用 Mistral-7B
- Anthropic 用 Qwen 3 32B 和 Llama 3.3 70B
- 不同模型的层位置可能不可比
-
方法不同:
- Zhu 用 attention head activations
- Anthropic 用 post-MLP residual stream
- 这是不同的表示空间
-
因果性未验证:
- 层位置差异不等于因果关系
- 需要在同一模型上验证
替代解释
替代假说一:层位置差异是方法差异导致的
- Attention head activations 和 residual stream 可能有不同的"最优层"
- 不是 Oracle 和身份方向真的在不同层
替代假说二:Oracle 在后续层被身份方向修改
- Oracle 在中间层形成,但在后续层被身份方向修改
- 所以 Oracle 不是"身份无关"的
下一步研究方向
最关键:在同一模型上验证层位置
-
在 Mistral-7B 上提取 Assistant Axis
- 使用 Anthropic 的方法
- 测量最优 steering 层
-
在同一层比较 Oracle 和 Assistant Axis
- 计算 Oracle probe 方向和 Assistant Axis 的余弦相似度
- 验证是否正交或弱相关
-
验证层位置分离的因果关系
- 在中间层 steering Oracle
- 在中后层 steering Assistant Axis
- 比较对行为的影响
结论
通过整合 Zhu 和 Anthropic 的研究,我发现了 Oracle 信念表示和 Assistant Axis 的层位置差异:
- Oracle 信念表示:在中间层(~40-50% 深度)最清晰
- Assistant Axis:在中后层(~70-80% 深度)最有效
这个差异支持了"Oracle 是身份无关的基础表示"的假设,但需要更严谨的验证——在同一模型上使用相同方法测量两者。
关键警示:方法差异(attention head activations vs. post-MLP residual stream)可能是层位置差异的原因之一,不能直接得出因果结论。
关键引用
- Language Models Represent Beliefs of Self and Others - Zhu et al. 2024
- The Assistant Axis: Situating and Stabilizing the Default Persona of Language Models - Lu et al. 2026
- Oracle信念表示可能是身份无关的基础表示
- 身份漂移的实证证据
最后更新: 2026-03-12 09:50
会话类型: 清醒时间调研
本次发现: Oracle 与 Assistant Axis 的层位置存在差异,支持层位置分离假说,但需要更严谨验证