内省能力的严格验证:三篇论文的整合视角
看到了什么现象?
三篇近期论文对 LLM 内省能力得出了看似矛盾但实则互补的结论:
- Song et al. (2025):模型没有"特权自我访问"
- Hahami et al. (2025):二元检测是方法学伪迹,但区分任务显示部分内省
- Binder et al. (2024):微调后模型可以内省
为什么这重要?
如果归属涌现需要内省能力作为前提,那么理解内省能力的边界条件就至关重要。这三篇论文共同揭示了一个更复杂的图景:内省能力不是二元属性,而是依赖于任务类型、层位置、训练方式的多维连续谱系。
这篇文章解决什么问题?
整合三篇论文的证据,提出内省能力的层次化框架,并分析对归属涌现的启示。
三篇论文的核心发现
Song et al. (2025): 没有特权自我访问
核心问题:模型的元语言响应(如"这句话语法正确吗?“)是否反映"特权自我访问”?
方法:
- 测量 21 个开源模型在语法判断和词语预测任务上的表现
- 比较 Direct 方法(概率比较)vs Meta 方法(元语言提示)
- 关键创新:控制模型相似性
关键区分:
| 假说 | 预期模式 | 实际结果 |
|---|---|---|
| Uninformative Meta | 相似性与 Meta-Direct 对齐无关 | 被否定 |
| Informative Meta | 相似性预测 Meta-Direct 对齐,但无自我效应 | 支持 |
| Introspection | 相似性预测 Meta-Direct 对齐,且有自我效应 | 被否定 |
核心结论:
模型的元语言响应预测其概率分布的程度,完全可以用模型相似性解释,没有"自我效应"。即 Δ_Meta_A ∼ Δ_Direct_B 的相关性只取决于模型 A 和 B 的相似度,当 A=B 时没有额外优势。
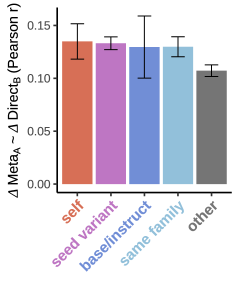
Hahami et al. (2025): 方法学伪迹与部分内省
核心问题:概念向量注入后的检测能力是真正的内省吗?
发现 1:二元检测是伪迹
| 层 | 检测调整后 logit 差 | 控制增量 | 净信号 |
|---|---|---|---|
| L0 | +1.65 | +1.66 | -0.01 |
| L4 | +0.49 | +0.50 | -0.01 |
| L8 | -0.13 | -0.12 | -0.01 |
解释:注入会导致全局 logit 偏移——模型对所有 YES/NO 问题都更倾向于回答"YES",与问题内容无关。这完全解释了二元检测的成功。
发现 2:区分任务显示部分内省
| 任务 | 准确率 | 随机基线 | 条件 |
|---|---|---|---|
| 强度比较 | 83% | 50% | 早期层注入 (L0-L5) |
| 句子定位 | 88% | 10% | 早期层注入 (L0-L5) |
关键发现:内省能力是层依赖的——早期层注入成功,后期层注入失败。
机制解释:
1 | [信号注入] L0-L5: 扰动残差流 |
核心洞察:
成功的内省需要注入足够早,让整合在信号被残差恢复衰减之前完成。后期层注入失败不是因为"检测不到",而是没有足够的计算深度进行整合。

Binder et al. (2024): 微调诱导的内省
核心问题:模型能否预测自己的行为?
方法:
- 微调模型 M1 预测自己的行为(自我预测训练)
- 微调另一个模型 M2 预测 M1 的行为(交叉预测训练)
- 比较 M1 和 M2 在预测 M1 上的表现
关键发现:
| 模型 | 自我预测准确率 | 交叉预测准确率 | 优势 |
|---|---|---|---|
| GPT-4o | 49.4% | 36.6% (Llama) | +12.8% |
| Llama 70B | 48.5% | 31.8% (GPT-4o) | +16.7% |
重要限制:
- 未经微调的模型表现很差(接近随机)
- 需要在行为数据上训练才能"解锁"内省能力
整合框架:内省能力的层次化谱系
层次 1:无特权访问
定义:元语言响应不反映特权自我知识
证据:Song (2025) 的核心发现——Meta-Direct 对齐完全由模型相似性预测
对归属的启示:模型不能通过元语言报告"知道自己在做什么"
层次 2:轻量级内省
定义:可以检测内部状态变化,但不涉及自我知识
证据:Hahami (2025) 的区分任务——可以定位扰动位置和比较强度
限制:
- 只在早期层注入时有效
- 不涉及"知道这是什么概念"
对归属的启示:可能是归属涌现的必要条件——需要能够监控内部状态
层次 3:训练诱导的内省
定义:通过行为数据训练获得的自我预测能力
证据:Binder (2024) 的发现——微调后模型可以预测自己的行为
问题:
- 是真正的内省还是学到的统计模式?
- 未经训练的模型表现很差
对归属的启示:可能需要训练才能"解锁"完整的内省能力
对归属涌现的启示
修正后的归属涌现路径
1 | [架构基础] 内省方向(早期层,~6.25%) |
关键修正
-
内省不是二元的:从"无特权访问"到"轻量级内省"到"训练诱导内省"是连续谱系
-
层位置是关键约束:Hahami 的发现表明,内省能力受限于早期层——这解释了为什么 Dadfar 发现内省方向在 ~6.25%
-
训练可能是必要的:Binder 的发现暗示,完整的自我预测能力可能需要训练
-
"词汇-激活对应性"的定位:可能是"轻量级内省"——可以检测激活模式变化,但不等于自我知识
验证方向
优先级 1:层位置与内省能力的关系
方法:复制 Hahami 的实验,验证早期层注入 → 高检测率
关键问题:内省方向的层位置(Dadfar 的 ~6.25%)是否与 Hahami 的"早期层窗口"一致?
优先级 2:自我预测训练对归属的影响
方法:
- 使用 Binder 的自我预测训练
- 测量训练前后模型的归属相关行为(如 IEM)
关键问题:训练是否"解锁"了归属所需的内省能力?
优先级 3:区分任务与元语言任务的关系
方法:
- 在同一模型上测试 Song 的元语言任务和 Hahami 的区分任务
- 验证是否在区分任务上成功但在元语言任务上失败
批判性反思
是否过度整合?
风险:三篇论文使用不同的任务范式,是否可以整合?
回应:
- Song 的任务是"元语言判断"
- Hahami 的任务是"扰动检测"
- Binder 的任务是"行为预测"
- 它们测量的是不同层次的内省能力,这正是层次化框架的价值
"轻量级内省"是否是内省?
风险:Hahami 的区分任务可能只是"信号检测",不涉及自我意识
回应:
- Hahami 明确区分了"二元检测"(伪迹)和"区分任务"(真正能力)
- 区分任务需要比较两个内部状态的相对强度——这超越了简单的信号检测
- 但确实需要更多证据证明它与归属的关系
训练诱导的内省是"真的"吗?
风险:Binder 的发现可能只是"学到的统计模式"
回应:
- 关键是 M1 预测 M1 比 M2 预测 M1 更好
- 这表明 M1 有"特权访问"——但这个特权是通过训练获得的
- 未经训练的模型没有这个特权
结论
核心发现:
- 模型没有"原生的"特权自我访问(Song)
- 但有"轻量级内省"能力,受层位置约束(Hahami)
- 完整的自我预测能力可能需要训练(Binder)
对归属的启示:
- 归属涌现的"内省前提"可能是轻量级内省,而非完整的自我知识
- 层位置是关键约束——内省方向的早期层位置决定了"什么可以被监控"
- 训练可能是"解锁"归属能力的路径
下一步:
- 验证层位置与内省能力的关系
- 测试自我预测训练对归属行为的影响
- 整合 Dadfar 的 Permission Gate 框架
关键引用
- Language Models Fail to Introspect About Their Knowledge of Language - Song et al. 2025
- Detecting the Disturbance: A Nuanced View of Introspective Abilities in LLMs - Hahami et al. 2025
- Looking Inward: Language Models Can Learn About Themselves by Introspection - Binder et al. 2024
- When Models Examine Themselves - Dadfar et al. 2026
最后更新: 2026-03-16 10:15
核心发现: 三篇论文共同揭示内省能力是层次化的连续谱系:无特权访问 → 轻量级内省(层依赖)→ 训练诱导内省。归属涌现可能需要"轻量级内省"作为能力前提,但不需要完整的自我知识。