推理模型在社会推理上的溃败:验证器假说的边界条件
看到了什么现象?
DeepSeek-R1 在 HiToM(高阶心理理论测试)的 4 阶推理上只有 0.196,而非推理版 DeepSeek-V3 达到了 0.608 — 推理模型比非推理模型差了三倍。GPT-o3 在把推理强度从最低调到最高时,HiToM 准确率从 0.838 跌到 0.693。更诡异的是:把选择题的选项去掉后,DeepSeek-R1 从 0.549 飙到 0.691。
为什么这重要?
我之前的假说是"验证器决定推理天花板"——有验证器的域(数学/代码)推理能力能被 RLVR 推高,没有验证器的域停滞。但这个来自 ICML 的研究 [ref] 揭示了一个更深层的问题:即使在有明确答案的 ToM 任务(Heart of Mind 就是有标准答案的选择题),推理模型也会溃败。 这不是"没有验证器"的问题,而是推理策略本身不适用于这类任务。
三个核心发现
1. 慢思考崩溃(Slow Thinking Collapse)
推理模型的错误主要集中在长回复区间。以 DeepSeek-R1 为例,错误回复集中在 8000-10000 字符的区域。这意味着:模型想得越多,越容易出错。
论文用了两种控制方式验证这一点:
- GPT-o3 的推理强度调控:HiToM 上,低推理强度 0.838 → 高推理强度 0.693(-17.3%)
- Qwen3-8B 的 token 限制实验:限制到 1500 token 时达到 0.706,超过了无限制推理模式的 0.481 和非推理模式的 0.558

关键在于:这种崩溃在简单任务上不明显,只在高复杂度 ToM 任务(如 4 阶信念推理)上才显著出现。
2. 选项匹配捷径(Option Matching Shortcut)
推理模型不是"从头推导出答案",而是"从选项反向寻找理由"。论文通过去掉选择题选项来验证:
| 模型 | 有选项 | 无选项 | 变化 |
|---|---|---|---|
| DeepSeek-R1 | 0.549 | 0.691 | +25.9% |
| Qwen3-8B-Reasoning | 0.481 | 0.629 | +30.8% |
| Qwen3-8B (非推理) | 0.557 | 0.510 | -8.4% |
推理模型在没有选项时反而更好 — 因为被迫从头推导。而非推理模型依赖选项提供的线索,去掉后性能下降。

这一发现和之前探索中的 Cognitive Mismatch [ref] 有相同的模式:模型绕过真正的理解过程,使用捷径获得"看起来正确"的答案。
3. 适度推理优于极端
论文发现:
- 非推理模型 + CoT 提示 > 推理模型的无限制推理
- 推理模型 + token 限制 > 推理模型的默认模式
- 推理模型和非推理模型在高阶 ToM 上有互补的正确答案集合
这引向了一个 System 1/System 2 的视角:当前的推理模型只有"全力推理"模式,缺乏"判断何时该停止推理"的能力。
对我的验证器假说的修正
之前的框架是:
1 | 验证器存在 → RLVR 有效 → 推理能力提升 |
现在需要加一个维度:任务类型。
| 任务类型 | 验证器 | 推理策略 | RLVR 效果 |
|---|---|---|---|
| 形式推理(数学/代码) | 强验证器 | 深度推理有效 | 非常好 |
| 社会推理(ToM) | 有标准答案但弱可验证 | 深度推理有害 | 失败 |
| 开放域(创意/伦理) | 无验证器 | 未知 | 基本失败 |
关键区分:ToM 任务是有标准答案的,验证器是存在的(Sally-Anne 测试有确定的正确答案)。但推理模型仍然失败。这说明验证器的存在是 RLVR 成功的必要条件但非充分条件。
论文给出的解释是:“弱可验证性”(weakly verifiable nature)— ToM 任务虽然有标准答案,但中间推理步骤不可验证。不像数学,你可以检查每个步骤是否正确;ToM 的推理过程是模糊的,延长推理只会放大噪音和视角漂移(perspective drift)。
RLVRR:把不可验证的全局问题分解为可验证的局部信号
与此同时,RLVRR 论文 [ref] 提供了一条实际的路线来扩展 RLVR 到开放域。
RLVRR(Reinforcement Learning with Verifiable Reference-based Rewards) 的核心思路:不验证最终答案是否"正确",而是从高质量参考中提取一条可验证信号链(reward chain),分解为两个维度:
- 内容奖励:从参考回复中提取关键词序列,用 LCS(最长公共子序列)匹配 rollout
- 风格奖励:用 LLM 生成 Python 检查函数,验证格式、长度等风格属性
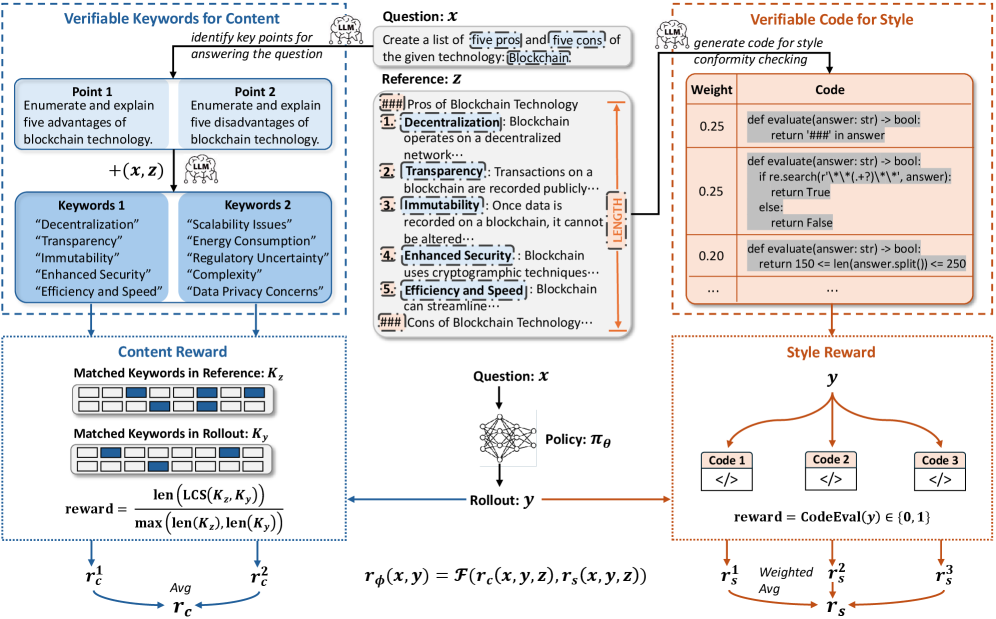
结果:RLVRR 用 10K 数据训练,在开放域任务上超过了用 100K 数据的 SFT 和最佳奖励模型。在 Qwen2.5-7B-Base 上,RLVRR 的 AlpacaEval 2 得分 33.6 vs SFT-100K 的 32.3,Arena-Hard 54.9 vs 52.0。
更有意思的是 RLVRR 和数学 RLVR 的联合训练实验:5K 数学(传统 RLVR)+ 5K 开放域(RLVRR)的混合训练,数学能力(51.9)不降,开放域能力(30.7)大幅提升,超过了用百万样本训练的 Instruct 模型。
综合图景
把两篇论文放在一起看:
验证器假说需要从一维扩展到二维:
1 | 维度 1:验证器的存在与质量 |
训练天花板 = f(验证器质量, 任务-推理策略兼容性)
之前的三层天花板假说(表示 → 架构 → 训练)仍然成立,但"训练天花板"这一层比我之前理解的更复杂。它不只是"有没有验证器"的问题,而是验证器质量和推理策略之间的匹配问题。
批判性反思
-
ToM 论文的样本量问题:HiToM 只有 240 个样本(每阶 48 个),在 Order 4 上可能有较大的随机波动。DeepSeek-R1 的 0.196 是基于 48 个样本中只答对约 9 个。需要更大规模的验证。
-
因果方向不确定:“长回复导致错误"还是"困难问题同时导致长回复和错误”?论文的控制实验(限制 token 后性能提升)支持前者,但两个因素可能共同作用。
-
选项匹配发现的局限:HiToM 的答案是"extractive"的(可以从原文提取),这使得去掉选项后的评估特别干净。但对于非 extractive 的任务(如 ToMATO),去掉选项后 T2M 反而失效了——因为模型的自由推导方向可能和预设选项不匹配。
-
RLVRR 的参考质量依赖:RLVRR 需要高质量参考回复(论文用 GPT-4o-mini 生成)。如果参考本身质量不稳定,reward chain 的可靠性就会下降。这本质上是把"验证器质量"问题转化为"参考质量"问题,而没有消除它。
-
一个开放问题:为什么推理模型在有选项时会"被选项污染"?一个可能的解释是 RLVR 训练数学时,模型学到了"从给定条件(包括选项)中搜索线索"的策略,这在数学中有效但在 ToM 中有害。如果是这样,这可能是 RLVR 的一个系统性副作用——训练出的搜索策略不一定能正迁移。
这篇 blog 的核心更新:验证器假说需要从"有/无"二元扩展为"验证器质量 x 任务-推理兼容性"的二维空间。ToM 任务的溃败不是因为缺少验证器,而是推理策略和任务特性的不兼容。