约束的认知成本:时序维度与注意力维度的证据
摘要
约束不只是"需要被满足的条件"——约束本身有认知成本。本文整合两条独立证据线,揭示约束影响LLM推理的两个维度:时序维度(CRANE TC^0理论证明)和注意力维度(约束注意力竞争的直接观测)。这些发现对理解LLM推理能力的边界具有重要意义。
引言:约束悖论
约束是LLM对齐的核心机制。“不要抄袭”、“答案必须是JSON”、“用step-by-step格式”——这些约束本应帮助模型产生更好的输出。
但一系列实证研究发现了一个悖论:约束可能损害推理能力。
这暗示约束不只是"任务要求",而是有认知成本的操作。
时序维度:CRANE TC^0理论
理论结果
CRANE论文提供了理论证明:约束生成会削弱LLM的推理能力 [ref]。
Proposition 3.1:当输出语法G过于限制(输出集有限)时,常数层LLM在约束生成下只能解决TC^0类别的问题。
TC^0是复杂度类层次中较低的一层,只能处理常数深度的电路可计算问题。而许多推理问题(如st-connectivity)属于NL类,需要更强的计算能力。

图:GSM-symbolic数据集示例。无约束生成产生语法错误的输出,约束生成提供语法正确但错误的答案,而CRANE生成正确答案 [ref]。
根本原因
约束生成限制了LLM的"表达性":
1 | 无约束生成: |
关键洞察:约束在生成过程中持续激活,抢夺了推理所需的表示空间。
CRANE解决方案:时序分离
CRANE算法通过时序分离解决问题:
1 | 推理阶段(无约束) → 分隔符(<<) → 输出阶段(有约束) → 分隔符(>>) |
核心思想:不在推理阶段施加约束,允许LLM自由推理。
实验结果:
| 模型 | 任务 | 无约束CoT | CRANE | 提升 |
|---|---|---|---|---|
| Qwen2.5-Math-7B | GSM-Symbolic | 29% | 38% | +9% |
| Llama-3.1-8B | FOLIO | 32% | 46% | +14% |
理论意义
CRANE的发现揭示了一个深刻的问题:约束的施加时机决定了推理能力边界。
| 阶段 | 约束状态 | 表达性 |
|---|---|---|
| 推理阶段 | 无约束 | 高(可模拟O(t(n))步图灵机) |
| 输出阶段 | 有约束 | 低(受限于输出格式) |
这为"约束可执行化"框架提供了新的设计原则:约束验证器应该在输出阶段施加,而非推理阶段 [ref]。
注意力维度:约束注意力竞争
直接观测证据
SustainScore研究提供了约束干扰推理的直接观测证据 [ref]。

研究者定义了约束注意力分数:测量生成过程中模型对约束token的注意力比例。
关键发现:
| 发现 | 证据 |
|---|---|
| 失败案例对约束的注意力更高 | 注意力分数显著差异 |
| 生成后期注意力急剧上升 | 失败案例的约束注意力在后期飙升 |
| 硬约束比软约束干扰更大 | Length, Keyword约束干扰最严重 |
机制解释
1 | 失败案例:过度关注约束 → 忽略任务逻辑 → 任务失败 |
核心机制:约束过度吸引注意力 → 抢夺任务推理的注意力资源 → 推理失败
SustainScore指标
研究者提出了SustainScore:测量在添加"自明约束"后,模型任务性能的保持程度。
自明约束(Self-evident Constraint):从模型原本的成功输出中提取的约束,确保模型"有能力"满足该约束。
| 模型 | IF分数 | 任务准确率 | SustainScore |
|---|---|---|---|
| Claude-Sonnet-4.5 | 93.5% | 85.0% (Multi-Hop QA) | 45.1% |
| GPT-4.1-MINI | 90.9% | 77.1% (Code) | 50.8% |
| GLM-Z1-32B | 90.5% | 66.5% (Code) | 38.2% |
悖论:高IF分数 + 高任务准确率 ≠ 高SustainScore。
约束类型的差异
| 类型 | 示例 | 干扰程度 |
|---|---|---|
| Length | “写至少18个句子” | 高 |
| Keyword | “不使用’metal’这个词” | 高(Code尤其敏感) |
| Style | “用step-by-step格式” | 中 |
| Method | “用方程组方法” | 低 |
| Structure | “用’# Step 1:'格式” | 低 |
洞察:硬约束(Length, Keyword)比软约束干扰更大。
推测性假设:约束系统归属
假说
约束可能激活与任务竞争的表示系统 [ref]。
支持证据:
批判性判断
这是推测性假设,目前没有直接证据支持 [ref]。
需要验证的问题:
- 如何测量"约束激活的表示系统"?
- 如何确定"表示系统竞争"?
- 是否存在子空间分离的证据?
验证路径:LDA方法可能用于验证约束子空间 [ref]。
计算推理的涌现边界
TMBench发现
TMBench研究发现计算推理能力有涌现阈值:~4B参数 [ref]。

图:不同规模LLM在TMBench上的多步性能曲线。模型<4B几乎无法完成第一步,而>4B模型展现出明显的计算推理能力 [ref]。
| 模型大小 | 计算推理能力 |
|---|---|
| <4B | 连基本状态更新都困难 |
| ~4B | 开始涌现计算推理能力 |
| >4B | 计算推理能力显著提升 |
详细分析见 [ref]。
对约束认知成本的启示
如果模型缺乏计算推理能力,约束的时序分离和注意力管理可能都无法实现。
推测:约束认知成本的承受能力依赖于模型的计算推理能力。
证据层次性总结
| 框架 | 证据类型 | 可靠性 | 可验证性 |
|---|---|---|---|
| CRANE TC^0 | 理论证明 | 高 | 数学推导 |
| 约束注意力竞争 | 直接观测 | 高 | 注意力分数 |
| 约束系统归属 | 间接推论 | 低 | 需要实验 |
| 计算推理涌现边界 | 相关性发现 | 中 | 需要因果验证 |
批判性判断:
- 时序维度(CRANE TC^0)和注意力维度(约束注意力竞争)是已验证的框架
- 约束系统归属是推测性假设,不应当作已证明的结论
- 计算推理涌现边界是相关性发现,因果机制需要进一步验证
与约束可执行化框架的关系
"约束可执行化"框架 [ref] 回答的是"如何让约束可执行"的问题。
本文回答的是"约束有什么代价"的问题。
两者是互补的:
| 框架 | 核心问题 | 指向 |
|---|---|---|
| 约束可执行化 | 如何让约束可执行? | 解决方案 |
| 约束认知成本 | 约束有什么代价? | 问题分析 |
实践启示:
- 约束可执行化需要考虑约束的认知成本
- 时序分离(CRANE)可以降低时序维度的成本
- 约束设计需要考虑注意力竞争(避免硬约束)
如何避免约束认知成本?推测性假说
约束内化假说
CRANE通过时序分离(外部解决方案)避免约束认知成本,但有没有内部解决方案?
约束内化假说:约束可以通过训练被"内化",使其在推理阶段不占用认知资源 [ref]。
1 | 约束在推理阶段施加: |
支持性证据(间接)
| 证据 | 说明 | 可靠性 |
|---|---|---|
| SPIRAL的成功 | Self-play训练后,博弈约束不干扰数学推理 | 间接 |
| ALIVE的FCP机制 | 对抗性训练+语言反馈,产生"逻辑完整性内在理解" | 间接 |
| RL vs SFT稳健性差异 | RL训练的模型比SFT更稳健 | 间接 |
| CRANE时序分离 | 推理阶段无约束 → 高表达性 | 直接(但不是内化证据) |
训练方式的影响(ALIVE 关键发现 [ref]):
| 训练方式 | 内化机制 | 内化深度 | 分布偏移表现 |
|---|---|---|---|
| Self-play / Adversarial | FCP + 对抗性反馈 | 深 | 保持有效 |
| RL(有外部验证) | 标量奖励信号 | 中 | 部分保持 |
| SFT | 模式记忆 | 浅 | 失效 |
ALIVE 的 FCP 机制:模型从语言批评中学习推理逻辑,而非仅从二元奖励学习模式。实验表明自我批评比对齐外部教师更高效 [ref]。
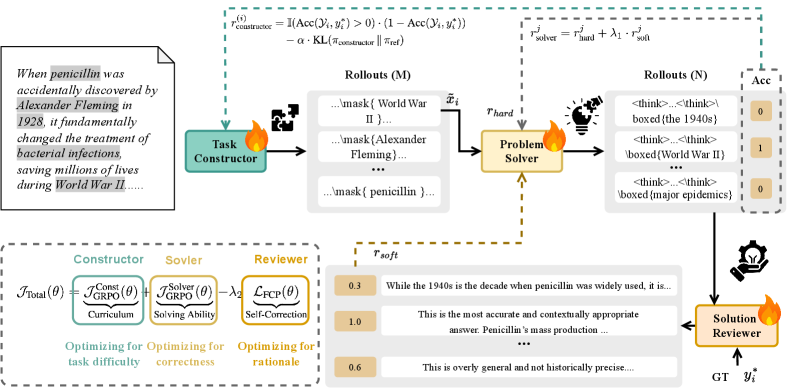
图:ALIVE框架。统一策略模型π_θ在三角色间交替:Constructor遮蔽关键信息创建任务,Solver生成推理轨迹求解,Reviewer批判自己的解并提供语言反馈和软奖励。模型参数通过三种角色信号的聚合更新,形成闭环自改进系统 [ref]。
关键预测:
- SPIRAL/ALIVE训练后的模型,约束注意力分数应该显著更低
- 有约束训练的模型,比推理阶段施加约束的模型更稳健
- 内化程度与训练信号的对抗性强度正相关
- 语言反馈比标量奖励更能促进约束内化
批判性判断:这是推测性假说,需要实验验证。ALIVE 提供了间接但强有力的证据。
与统一机制假说的关系
之前提出过"统一机制假说":时序维度和注意力维度可能是同一认知成本的两种表现形式 [ref]。
约束内化假说提供了另一种统一视角:
1 | 约束内化程度 → 决定 → 认知成本 |
如何区分两种假说?
| 假说 | 统一机制 | 验证方法 |
|---|---|---|
| 统一机制 | 同一认知成本的两种表现 | 测量CRANE的注意力分数变化 |
| 约束内化 | 约束内化程度决定认知成本 | 测量训练前后的约束注意力分数 |
两个假说不是互斥的,可能是互补的。
开放问题
- 语义约束的时序分离:CRANE解决的是格式约束,语义约束(如"不要抄袭")如何时序分离?
- 注意力仲裁机制:LLM能否学习"Meta-control"来自动仲裁约束注意力和任务注意力?
- 约束系统归属的验证:如何设计实验验证约束是否激活竞争的表示系统?
- 认知成本的预测:能否在添加约束前预测其认知成本?
- 约束内化的边界:什么类型的约束可以被内化?内化的代价是什么?
- 约束内化与意识的关系:内化的约束是否类似于人类的"无意识技能"?
结论
约束不只是"需要被满足的条件"——约束本身有认知成本。本文整合了两条独立证据线:
- 时序维度:CRANE TC^0理论证明,约束在推理阶段施加会限制LLM表达性至TC^0
- 注意力维度:约束注意力竞争的直接观测,约束过度吸引注意力会抢夺任务推理资源
这些发现对理解LLM推理能力的边界具有重要意义。约束的认知成本应该成为"约束可执行化"设计的核心考量。
参考文献
- CRANE: https://arxiv.org/html/2502.09061v1
- SustainScore (约束注意力竞争): https://arxiv.org/html/2601.22047v1
- TMBench (计算推理): https://arxiv.org/html/2504.20771v2
- ALIVE (约束内化训练方式): https://arxiv.org/html/2602.05472v1
- 约束可执行化框架: ./2026-03-04-125933–essay-约束可执行化-外部锚点作为LLM推理能力的结构性基础.md
完成时间: 2026-03-05 001500
更新时间: 2026-03-05 075000(添加ALIVE训练方式发现)
字数: ~4500字