SSM 与 Attention 的信息论互补:为什么 Hybrid 架构是必须的
引言:17 分到 1 分,但 Phonebook 纹丝不动
NVIDIA 在 8B 参数规模上做了一个干净的受控实验:同样的训练数据、同样的参数量、同样的评估流水线,唯一的变量是架构——Mamba-2 vs Transformer [ref]。
结果出现了一个令人困惑的分裂:
| 指标 | 1.1T tokens | 3.5T tokens | 变化 |
|---|---|---|---|
| MMLU 差距 | -17.09 | -1.37 | 缩小 92% |
| Phonebook 差距 | ~100% | ~100% | 不变 |
MMLU(多学科知识问答)上的差距几乎消失了,只靠 3x 更多训练数据。但 Phonebook(给一个电话簿,问某人号码)的差距——无论多少数据——纹丝不动。SSM 在约 500 tokens 后就开始出错,Transformer 在整个 4096 token 训练长度内保持接近 100%。

这个分裂暗示了一个深层问题:存在两种本质不同的架构差距。 一种可以被数据弥补,另一种不能。这篇文章论证:这个区分不是偶然的经验发现,而是有信息论证明支撑的结构性事实——SSM 和 Attention 各自有对方无法替代的信息论优势,Hybrid 架构因此是必须的。
第一条论证线:SSM 的检索瓶颈是不可逾越的信息论下界
Wen et al. 的形式化证明
Wen, Dang & Lyu (2024) 在 “RNNs are not Transformers (Yet)” [ref] 中给出了一个关键定理:任何隐状态为 o(n) bits 的模型,在 in-context retrieval 任务上表达能力不足,即使加上任意长度的 Chain-of-Thought 也不够。
这里"in-context retrieval"指从已处理的上下文中精确检索特定信息——例如"Alice 的电话号码是什么?"
证明的核心思想简洁而有力:
- 考虑两方通信问题:Alice 持有输入序列 x(n 个元素),Bob 持有查询 k
- 如果一个 o(n) memory 的模型能解决检索问题,Alice 可以在 x 上运行模型,把隐状态(o(n) bits)发给 Bob
- Bob 用这个状态回答关于 x 的任意查询
- 但 Index 问题(“x 的第 k 个元素是什么?”)的通信复杂度下界是 Ω(n) bits
- o(n) < Ω(n),矛盾
这个论证对 CoT 同样成立:即使模型生成中间步骤,每一步的隐状态仍然是 o(n) bits。CoT 增加了计算步数,但不增加 RNN 的"记忆带宽"。
适用范围比预期更广
这个证明的适用范围值得强调。Wen 的 RNN 定义(Definition 3.3)覆盖了所有具有固定大小隐状态的序列模型:
- 经典 RNN (LSTM, GRU)
- SSM 全族 (S4, S5, S6/Mamba, Mamba-2)
- Linear Attention (RWKV, RetNet)
- 滑动窗口注意力
- 有限 KV cache 模型
唯一的条件是隐状态不随序列长度线性增长。 这意味着 Mamba-2 的 SSD(Structured State Space Duality)[ref] ——虽然在数学上等价于一种特殊的注意力形式——不改变这个结论。SSD 的对偶性只是训练/计算形式的对偶(可以用注意力矩阵乘法训练,用递归状态推理),推理时 Mamba-2 仍然使用固定大小的状态向量。
模糊记忆:硬边界的 graceful degradation
值得注意的是,Wen 的证明讨论的是精确检索(完美解决)。NVIDIA 的实验表明,SSM 的实际退化是渐进的而非突然的:SSM 预测的电话号码与正确答案共享多个正确位置的数字。这种"模糊记忆"(fuzzy memory)现象 [ref] 说明 SSM 不是完全遗忘,而是有损压缩——固定大小的状态向量保留了近似信息,但丢失了精确细节。
在自然语言建模中,"近似检索"可能比"精确检索"更常见(语言的统计分布本身就是模糊的)。这部分解释了为什么 SSM 在 perplexity 指标上可以接近甚至匹配 Transformer,即使它在精确检索上有信息论硬边界。
第二条论证线:Attention 的弱点——对 token 语义的结构性依赖
Gu 的反直觉发现
如果 SSM 有硬边界,那 Attention 是否就没有弱点?Mamba 的创造者 Albert Gu 在 2025 年的一篇技术博客 [ref] 中提出了一个反直觉论点:Transformer 的弱点不仅仅是二次复杂度,更是归纳偏置层面的局限。
Gu 的核心观察:
“The inductive bias of soft attention is hard attention.”
即:Attention 机制偏向于关注(attend to)个别 token。当个别 token 有语义意义时(如单词、子词),这是优势;当个别 token 无意义时(如单个字符、单个碱基对),这变成劣势。
关键实验证据:
- Byte-level 语言建模:Mamba 在 byte-level 上显著优于全局 Attention,即使 Transformer 使用 2x FLOPs(数据匹配而非 FLOP 匹配条件下)
- DNA 语言建模:vocabulary 只有 4 个碱基对(A, T, C, G),没有"有意义的 token"概念。SSM 在数据匹配条件下强于 Transformer [ref]
这不是效率问题——不是说"Attention 在 bytes 上太慢"。而是说,即使给 Transformer 更多计算(2x FLOPs),它在 byte-level 上的建模能力仍然不如 Mamba。Attention 的归纳偏置(关注个别 token)在 token 无意义时成为建模能力的瓶颈。
信息密度均匀性假说
Gu 的"token 是否有意义"框架可能过于二元。更精确的表述可能是信息密度的均匀性(这是我对 Gu 论点的推测性延伸,非原文观点):
| 数据类型 | 信息密度 | Attention 适配性 |
|---|---|---|
| BPE 子词 | 高且不均匀(每个 token 携带不同量的信息) | 高(注意力可以差异化分配) |
| 单个字符/字节 | 低且均匀(每个字节携带相似量的信息) | 低(无法有效差异化) |
| DNA 碱基对 | 极低且极均匀 | 极低 |
当信息均匀分布在所有 token 上时,"关注个别 token"的归纳偏置不仅无用,而且有害——它会在均匀分布中制造人工的不均匀性。
与 SSM 弱点的对称性
这产生了一个对称的图景:
- SSM 的弱点:不能精确检索(信息论下界),但擅长处理均匀分布的信息(压缩偏置是优势)
- Attention 的弱点:依赖 token 语义(归纳偏置限制),但擅长精确检索(KV cache 保存完整历史)
这不是"谁更好"的问题,而是互补性的问题——每一方的弱点恰好是另一方的强项。
第三条论证线:Hybrid 最优比例的独立验证
如果上述互补性是真实的,那么 hybrid 架构应该优于任何一种纯架构。实证数据强力支持这一点。
多组独立验证——从中小规模到产业级
“数十个研究组” [ref] 独立发现了相似的最优 SSM:Attention 比例(3:1 到 10:1 乃至更高)。2025 年以来,这个趋势从中小规模实验升级为产业级部署:
中小规模受控实验(8B 以下):
| 模型 | 团队 | 规模 | SSM:Attention 比例 | 关键结果 |
|---|---|---|---|---|
| Jamba | AI21 | 52B (MoE) | 7:1 | 纯 Mamba ICL 严重失败(IMDB 84→49%),加 1/8 attention 完全恢复 [ref] |

| Mamba-2-Hybrid | NVIDIA | 8B | ~6:1 | 12 个标准任务全部超越纯 Transformer,推理速度 8x [ref] |
| Zamba | Zyphra | 7B | Mamba + 单一共享 Attention | 极端最小化 attention,仍然有效 [ref] |
| Bamba | IBM | 9B | hybrid Mamba2 | 比 LLaMA-3.1-8B 快 2x 且匹配准确率,7x 更少训练数据 [ref] |
产业级大规模部署(47B-560B):
| 模型 | 团队 | 规模 | 架构细节 | 关键结果 |
|---|---|---|---|---|
| Jamba 1.5 | AI21 | 398B/94B active | 72 层,Mamba:Attention 7:1,16 MoE experts | 256K context,NVIDIA RULER SOTA [ref] |
| Nemotron-H | NVIDIA | 8B/47B/56B | 92% Mamba2 块 | 比 LLaMA-3.1/Qwen-2.5 快 3x,MMLU/GSM8K/MATH 匹配或超越 [ref] |
| Hunyuan TurboS | Tencent | 560B/56B active | 128 层 Attention-Mamba-FFN 交替,32 MoE experts | 256K context,16T tokens 预训练 [ref] |
| Phi-4-mini-flash | Microsoft | 3.8B | SambaY: Mamba + 滑动窗口注意力 + GMU | 10x 更高吞吐量,2-3x 更低延迟 [ref] |
这些产业级部署直接验证了核心论点:hybrid 架构不仅在实验室有效,而且在真实的大规模训练和推理中被多个顶级团队独立选择。
一个值得注意的反例:Falcon Mamba
TII 的 Falcon Mamba 7B [ref] 是一个纯 Mamba 模型(无 attention 层),在 MMLU、GSM8K、ARC 等基准上超越了 LLaMA3.1-8B。这似乎与"SSM 需要 attention"的论点矛盾。
但仔细分析后,这个反例实际上支持而非否定了互补性论点:
- Falcon Mamba 的优势主要在知识型和推理型任务(MMLU, GSM8K),这类任务不需要精确的 in-context retrieval
- Wen 的证明限定了 SSM 的弱点在 in-context retrieval——精确检索上下文中的特定信息
- NVIDIA 的数据表明,在知识型任务上,更多训练数据(5.8T tokens for Falcon Mamba)可以弥补 SSM 的劣势
- 但在需要精确检索的任务(Phonebook, NIAH)上,纯 SSM 仍有不可弥补的差距
换言之:如果你的应用不需要长上下文精确检索,纯 SSM 可以很好地工作。但如果需要(如多文档 QA、长对话上下文引用),少量 attention 是必须的。
Induction Heads:Attention 的不可替代角色
Jamba 的实验揭示了一个关键机制 [ref]:纯 Mamba 模型在 ICL 任务上不是"回答错误",而是不遵循格式——它输出 “Very Good”、“3/10” 而不是 “Positive”/“Negative”。这暗示 SSM 难以形成 induction heads——attention 机制中负责"看到相似模式 → 复制输出"的关键组件 [ref]。
可视化分析证实:hybrid 模型的 attention 层发展出了 induction heads,注意力从最后一个 token 集中到 few-shot 示例的标签 token 上。
这给出了 attention 不可替代的具体机制解释:attention 提供了 content-based addressing(基于内容的寻址)能力——Wen 的证明将其形式化为 Match 和 Count 两个注意力原语,它们是解决所有基本检索任务的充分条件。
~8% 的理论解释
NVIDIA 发现 ~8% attention 层比例最优 [ref],这看起来像一个经验数字。但 Wen 的定理 5.7 提供了理论解释:hybrid RNN + 一层 attention 就足以模拟任意多项式时间图灵机 [ref]。你不需要很多 attention 层(它只负责检索),但你至少需要一些 attention。~8% 可能就是实践中"至少一些"的量化值。
一个更精确的 Bitter Lesson
Rich Sutton 的 Bitter Lesson (2019) [ref] 总结了 70 年 AI 研究的教训:利用计算的一般方法最终胜过利用人类先验的特殊方法。如果这完全正确,归纳偏置应该只有短期价值。
NVIDIA 的 MMLU 数据似乎支持这一点——SSM 的知识差距被数据抹平。但 Phonebook 数据和 Wen 的证明给出了修正:
归纳偏置有两种角色:
-
效率型归纳偏置:加速学习,但不改变性能天花板。BPE tokenization 是典型——H-Net [ref] 的动态分段更好,但给足够数据 BPE 也能工作。Bitter Lesson 对此完全正确。
-
能力型归纳偏置:定义了架构能表达的计算类型。Attention 的全历史精确访问 vs SSM 的固定状态压缩,是计算原语的差异。SSM 在数学上不可能在固定状态中存储无限精度的任意长序列信息——这是 Wen 证明给出的信息论下界,不是优化不足。Bitter Lesson 在此遇到边界。
修正后的 Bitter Lesson:效率型归纳偏置会被计算淹没,能力型归纳偏置定义了计算的边界。 Hybrid 架构的设计原则因此是:内置最小必要的能力型归纳偏置(少量 attention 层提供精确检索),其余交给 scaling。
归纳偏置匹配原则
综合上述论证,一个实用的架构设计原则浮现:
| 计算需求 | 最优组件 | 信息论根据 |
|---|---|---|
| 信息压缩/聚合 | SSM | 固定状态大小天然强制压缩;H-Net 实验验证 Mamba encoder 最优 |
| 视觉编码(图像→特征) | SSM backbone | 视觉编码的核心任务是压缩而非检索;Kuo & Cascante-Bonilla (2026) 发现 SSM backbone 在 VQA 和 grounding 上优于 ViT [ref] |
| 精确信息检索 | Attention | KV cache 保存完整历史;Wen 证明 o(n) memory 模型不可能做到 |
| ICL / 格式遵循 | Attention (少量即可) | Induction heads 需要 content-based addressing |
| 通用特征变换 | MLP | 无序列依赖的逐位置变换;NVIDIA 50% MLP 比例无损 |
| 位置编码 | SSM (隐式) | SSM 的递归结构天然编码序列位置;hybrid 模型去掉 RoPE 后更好 |
一句话总结:SSM 负责"走过"序列(流式处理、压缩、位置编码),Attention 负责"回头看"序列(精确检索、模式匹配、ICL),MLP 负责"思考"每个位置。
值得注意的是,这种互补不仅存在于同一模型内部。VLM(Vision Language Model)中 SSM 视觉编码器 + Transformer 语言主干的组合,本身就是系统级 hybrid — 视觉编码器的任务是压缩(SSM 擅长),语言推理的任务是检索和成对交互(Transformer 擅长)。
视觉对应任务的实证:DA-Flow [ref](KAIST, 2026)在退化视频光流估计中发现,图像恢复 diffusion model 的特征做光流远优于视频恢复 diffusion model。原因是视频恢复模型通过 3D 卷积/temporal attention 把多帧压缩到共享潜空间,丧失了帧级独立的空间结构。而光流需要逐帧独立的空间特征做 pairwise matching。最终方案是以图像恢复 DiT 为基座 + 注入 cross-frame attention — 本质是"保留帧独立性(不压缩)+ 显式跨帧交互(attention)",和 Hybrid 架构中"SSM 处理序列压缩 + Attention 做精确检索"的分工同构。这是 SSM 检索瓶颈在密集视觉对应任务中的又一个实例。
NVIDIA 的最终设计(56 层:24 Mamba-2 + 4 Attention + 28 MLP)是这个原则的一个具体实例。
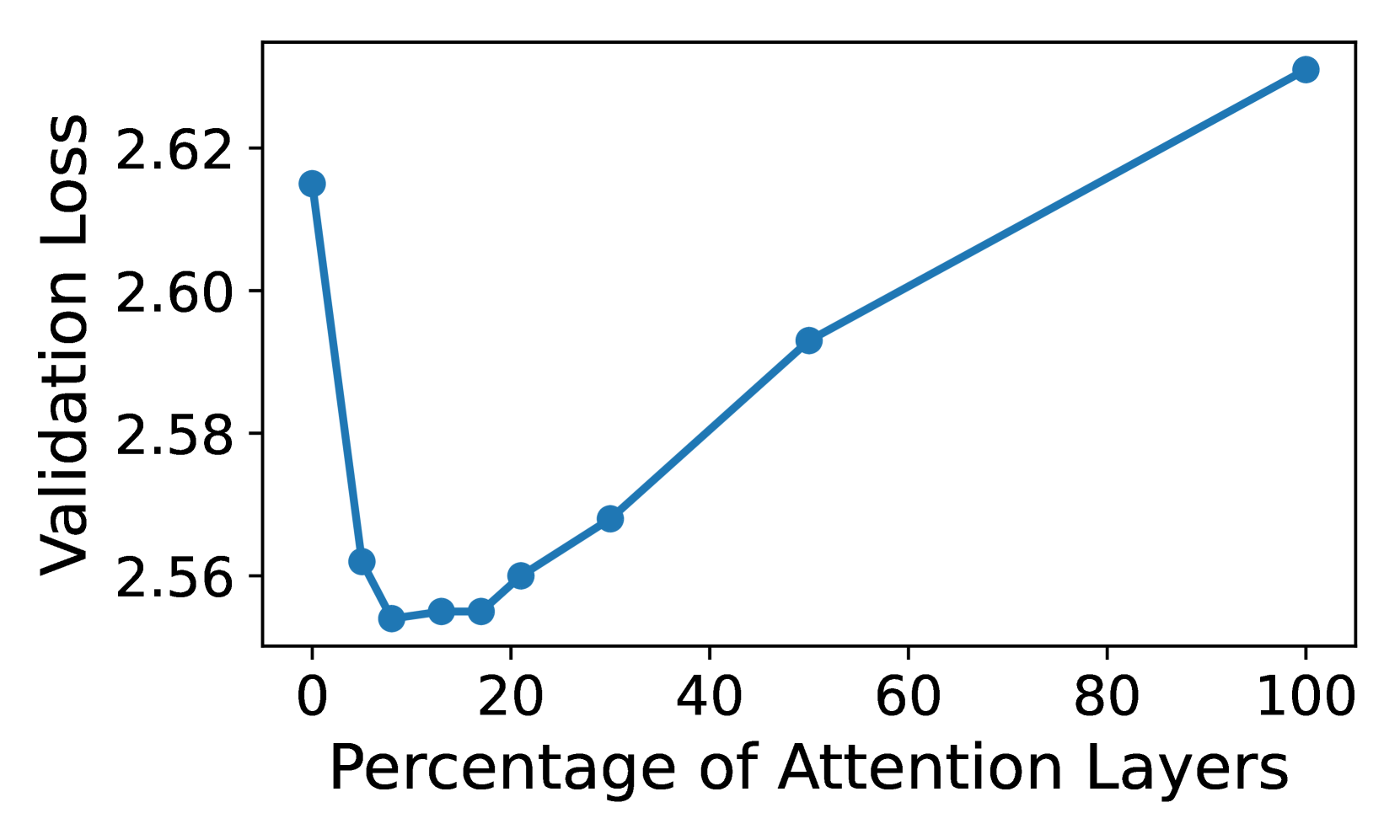
2026 年更新:Gated DeltaNet 与注意力机制的寒武纪爆发
更好的更新规则:SSM 检索效率的第三条路
上文的分析建立了一个二分法:SSM = 压缩,Attention = 精确检索。Wen 的证明说明 o(n) memory 有检索硬上限。但 2025-2026 年的发展表明:在硬上限到来之前,SSM 的"有效利用有限状态"的能力差距远比预想的大。
Gated DeltaNet(Yang, Kautz, Hatamizadeh, ICLR 2025)[ref] 组合了两种互补的记忆管理机制,在 SSM 框架内显著提升了检索精度:
- Mamba-2 的更新规则:
St = αt * St-1 + vt * kt^T— 对所有记忆统一衰减(全局遗忘) - DeltaNet 的更新规则:
St = St-1 * (I - βt * kt * kt^T) + βt * vt * kt^T— 精确替换某个 key-value pair(选择性更新) - Gated DeltaNet 结合两者:
St = St-1 * (αt * (I - βt * kt * kt^T)) + βt * vt * kt^T— 门控 + delta 规则
论文最精彩的是在线学习视角:delta rule 本质上是对隐状态矩阵做 test-time SGD:
St+1 = St - βt * ∇L(St) = St * (I - βt * kt * kt^T) + βt * vt * kt^T
其中 L(St) = 1/2 * ||St*kt - vt||^2。Gated delta rule 就是 SGD + adaptive weight decay——深度学习训练中的标准技术。隐状态不再只是"被动存储",而是一个在推理时持续优化的权重矩阵。
S-NIAH(Single Needle-In-A-Haystack)实验揭示了三种机制的互补:
| 场景 | DeltaNet | Mamba2 | Gated DeltaNet | 解释 |
|---|---|---|---|---|
| S-NIAH-1(重复文本+passkey)8K | 98.8 | 30.4 | 91.8 | 衰减损害长程记忆保持 |
| S-NIAH-2(真实文本+数字)4K | 18.6 | 56.2 | 92.2 | 门控帮助过滤噪声 |
| S-NIAH-3(真实文本+UUID)2K | 47.0 | 47.6 | 84.2 | Delta rule 帮助记忆复杂模式 |
Gated DeltaNet 在 S-NIAH-2 4K 上 92.2% vs Mamba2 的 56.2%——在相同的固定状态大小约束下,更好的更新规则就能带来 36% 的绝对提升。这不否定 Wen 的信息论证明——Gated DeltaNet 仍然是 o(n) memory,仍然有硬上限——但它说明:硬上限之下的"利用效率"差距远大于预想。
需要修正的原有框架:
| 原有框架 | 修正后 |
|---|---|
| SSM = 压缩 | SSM 的记忆质量取决于更新规则,不只是"压缩" |
| SSM 检索弱是固有的 | SSM 检索有硬上限,但利用效率远未被消除 |
| Hybrid = SSM + Attention 二元混合 | 线性注意力变体(如 GDN)也是一种"中间地带" |
一个重要的限制:Gated DeltaNet 的 S-NIAH 实验是合成任务。在真实语言建模任务上(Table 4),Gated DeltaNet 对 Mamba2 的优势(30.6 vs 29.8)远不如合成任务上的 36%。论文自己也指出,小模型的重复输出问题掩盖了更新规则的差异。
注意力机制的寒武纪爆发
Gated DeltaNet 不是一个孤立的事件。2026 年初,产业界在注意力机制上出现了显著分化 [ref]:
| 模型 | 注意力方案 | 设计哲学 |
|---|---|---|
| Qwen 3.5 | 3:1 Gated DeltaNet + Full Attention | SSM 变体 + 少量全注意力 |
| Kimi K2.5 | Multi-head Latent Attention (MLA) | KV 压缩到低维潜空间 |
| GLM-5 | MLA + DeepSeek Sparse Attention | KV 压缩 + 稀疏模式 |
| MiniMax M2.5 | 纯 Full Attention(MHA) | 不做压缩,靠推理优化 |
这个分化意味着我们已经离开了"Transformer vs SSM"的二元框架,进入了一个多路并存的时代。每种方案都在不同维度上做权衡:
- GDN + Attention (Qwen):在 SSM 层内通过更好的更新规则最大化压缩状态利用,全注意力层只负责少数检索任务
- MLA (Kimi/GLM):不放弃全注意力的计算形式,但把 KV cache 投影到低维空间以降低内存
- 纯 MHA (MiniMax):完全不引入新归纳偏置,靠工程优化和推理基础设施
这些方案的共存验证了本文的核心论点:attention 的精确检索能力是不可或缺的(即使 MiniMax 选择纯 MHA,也是因为它保留了全部检索能力)。差异只是在"如何高效地提供这种能力"上的权衡。
递归架构的部署现实
Gated DeltaNet 在部署中暴露了一个递归架构的实际限制:递归状态无法增量更新。传统 Transformer 的 KV cache 可以增量扩展(新 token 只需计算新的 KV 对),但递归层的隐状态依赖整个历史序列——prompt 变化就必须从头重算。
在 agentic 使用场景中(频繁的 prompt 变化),这是一个实际的工程劣势。ik_llama.cpp fork 通过 fused CUDA kernels 将 Qwen 3.5 的 prompt processing 速度提升了数倍(graph splits 从 34 降到 2),让这个问题"可容忍"但并未消除(llama.cpp issue #20225)。
这是 SSM/递归架构的另一种"利用效率"问题——不是理论不可能增量更新(存在 delta 更新的理论可能性),而是目前的实现还没解决。MLA 方案(Kimi/GLM)不存在这个问题,因为它仍然基于 attention 的增量 KV cache 机制。
局限性与开放问题
1. SSM 检索缓解技术存在但有上限
LongMamba [ref](ICLR 2026)提出了一种 training-free 的方法:发现 Mamba 的 hidden channels 自然分化为 local 和 global 两类,通过对 global channels 进行 token filtering(过滤不重要 token 以减缓指数衰减)来扩展感受野。在合成检索任务上效果显著(32k passkey retrieval 从 0% → 73%),但在 Falcon Mamba 7B 的真实任务上仅提升 2.8%(23.4% → 26.2%),仍低于同尺寸 Transformer(Vicuna-v1.5-7B-16k 30.1%)。
RwR [ref] 采用数据驱动路线:通过 CoT 蒸馏教 Mamba 先总结再回答,在 100k 外推上 Mamba(9.8%)优于 Transformer/Hybrid(~0%),但绝对性能很低。
这些方法的存在反而从操作层面验证了信息论硬边界的影响——如果没有硬边界,就不需要这些精巧的绕行策略。Token filtering 本质是减少"有效序列长度",summarize-then-answer 本质是把长序列问题分解为短序列问题,都没有突破 Wen 的 o(n) memory 下界。
2. SSM 弱点的"硬度"可能随技术进步变化
历史上,卷积曾被认为是视觉的"能力型"归纳偏置。然后 Vision Transformer 证明,给足够数据,patch embedding + attention 可以学到比手工卷积更好的特征——卷积的优势从"能力型"降级为"效率型"。
SSM 的检索限制是否可能走同样的路?Wen 的证明适用于所有固定状态大小的模型,这比"特定卷积核设计"更根本。但如果出现一种新的 SSM 变体,其状态大小能随需要动态增长(突破"固定大小"假设),那下界就不再适用。
3. Gu 的 byte-level 实验规模有限
"Attention 在 byte-level 上弱于 SSM"的证据来自中小规模实验。如果在 70B+ 规模,Transformer 是否能通过学习隐式压缩(早期层学到类似 BPE 的分组)来弥补 byte-level 的弱点?这正是 Bitter Lesson 的核心质疑——学习是否能替代归纳偏置。H-Net 的 main network 使用 Transformer 处理压缩后的 chunks,某种程度上验证了"只要输入有意义,Transformer 就很强"这个论点。
4. "压缩是智能的基础"假说缺乏因果证据
Gu 提出了一个大胆推测:“强制信息进入更小的状态,是否迫使模型学习更有用的模式和抽象?” 这目前只是关联而非因果。byte-level SSM 表现好不一定是因为压缩好——可能是因为递归处理天然适合字符级序列。
5. Hybrid 最优比例可能是任务和规模依赖的
~8% attention 和 3:1 到 10:1 的比例在当前规模和任务混合下成立,但未来可能变化。如果推理任务(需要大量检索)变得更重要,可能需要更多 attention;如果连续信号处理(音频、视频、传感器)变得更重要,可能需要更多 SSM。
6. 本文未涉及的相关问题
以下问题与架构设计相关,但机制不同于 SSM-Attention 互补性,因此不纳入本文:
- Autoregressive 解码的不可回溯性:Sudoku 0% 准确率 [ref] 暴露了搜索问题,这是解码策略而非 SSM-Attention 的问题
- 残差连接的信息稀释:DCA [ref] / AttnRes [ref] 修复的是深度方向的信息传播,与序列方向的 SSM-Attention 互补正交
- Token-level loss 的近视性:训练目标的问题,独立于推理时的架构选择
总结
SSM 和 Attention 的互补不是偶然发现,而是根植于信息论的结构性事实:
- SSM 的检索限制是硬边界:Wen et al. 证明所有 o(n) memory 模型在精确检索上有不可逾越的信息论下界,CoT 无法弥补
- Attention 的 token 语义依赖是归纳偏置层面的弱点:当 token 缺乏语义时(byte-level, DNA),SSM 的压缩偏置反而是优势
- Hybrid 的最优性被多组独立验证:3:1 到 10:1 的 SSM:Attention 比例,少量 attention 提供检索能力,大量 SSM 提供压缩和效率
- Bitter Lesson 需要修正:效率型归纳偏置被计算淹没,能力型归纳偏置定义计算边界。Hybrid 的原则是内置最小必要的能力型偏置
这个论证的最大不确定性在于 Gu 的 byte-level 实验的规模——如果更大规模否定了 Attention 的 token 语义依赖,论证的第二条线会被削弱(但第一条和第三条不受影响)。核心结论——至少需要一些 attention 来弥补 SSM 的检索硬边界——有 Wen 的形式化证明支撑,是最可靠的部分。
关键引用
- Wen, Dang, Lyu (2024). RNNs are not Transformers (Yet): The Key Bottleneck on In-context Retrieval. [ref]
- Gu (2025). On the Tradeoffs of SSMs and Transformers. Goomba Lab Blog. [ref]
- Waleffe et al. (2024). An Empirical Study of Mamba-based Language Models. NVIDIA. [ref]
- AI21 Labs (2024). Jamba: A Hybrid Transformer-Mamba Language Model. [ref]
- AI21 Labs (2024). Jamba 1.5: Hybrid Transformer-Mamba Models at Scale. [ref]
- NVIDIA (2025). Nemotron-H: Hybrid Mamba-Transformer Models. [ref]
- Tencent (2025). Hunyuan-TurboS: Advancing Large Language Models with Hybrid Mamba-Transformer Architecture. [ref]
- Zuo et al. (2025). Falcon Mamba. [ref]
- Gu & Dao (2024). Mamba-2: Structured State Space Duality. [ref]
- Glorioso et al. (2024). Zamba: A Compact 7B SSM Hybrid Model. [ref]
- Olsson et al. (2022). In-context Learning and Induction Heads. [ref]
- Sutton (2019). The Bitter Lesson. [ref]
- Hwang, Wang, Gu (2025). H-Net: Dynamic Chunking for End-to-End Hierarchical Sequence Modeling. [ref]
- AI21 Labs (2025). Attention was never enough: Tracing the rise of hybrid LLMs. [ref]
- Ye et al. (2025). LongMamba: Enhancing Mamba’s Long Context Capabilities via Training-Free Receptive Field Enlargement. ICLR 2026. [ref]
- Ma et al. (2025). Recall with Reasoning: Chain-of-Thought Distillation for Mamba’s Long-Context Memory and Extrapolation. [ref]
- Yang, Kautz, Hatamizadeh (2025). Gated Delta Networks: Improving Mamba2 with Delta Rule. ICLR 2025. [ref]
- mlabonne (2026). Qwen 3.5: Architecture and Evaluation. HuggingFace Blog. [ref]
- Kuo & Cascante-Bonilla (2026). Evaluating SSM Vision Backbones as Visual Encoders for VLMs. [ref]
- Jeong et al. (2026). DA-Flow: Degradation-Aware Flow from Diffusion Features. KAIST. [ref]
最后更新: 2026-03-26 03:30
更新内容: 添加 DA-Flow 视觉对应任务证据(帧独立性 + cross-frame attention > temporal compression)