LLM 自我识别的信息流:从预训练风格感知到身份标签驱动
摘要
LLM 能否识别自己的输出?过去一年的四篇独立实验研究给出了一幅比"能/不能"更微妙的图景:模型在内部表示中已经编码了区分自己与他人输出的信息(线性探测准确率 >90%),但这个信息在到达输出层时被严重衰减(绝对判断准确率仅 ~15%)。当给模型一个身份标签(如"你是 ChatGPT")时,自我偏好立刻出现且效果极端(Cohen’s d——衡量效应大小的标准化指标,0.8 以上通常视为大效应——竟然 > 4.0);但这个偏好跟随的是被分配的身份而非真实的身份——告诉 GPT 它是 Claude,它就偏好 Claude。
本文综合 Zhou et al. (2025)、Bai et al. (2025)、Lehr et al. (2025) 和 Ackerman & Panickssery (2025) 四篇论文的发现,构建出 LLM 自我识别的完整信息流模型。核心发现:自我识别不是单一能力,而是涉及至少三个独立机制的复合过程——预训练涌现的风格感知、post-training 创建的决策桥梁、以及身份标签驱动的 Self=Good 联想。这三个机制在不同层级运作,且可以被独立操控。
1. 问题:LLM 的"自我识别"到底在测什么?
2024 年以来,至少有六篇论文研究了 LLM 的"自我识别"能力。但它们测量的东西并不相同:
| 论文 | 任务 | 结果 | 测量的是什么? |
|---|---|---|---|
| Panickssery et al. 2024 [ref] | 成对比较:自己 vs 其他模型的文本 | GPT-4: 73.5% | 跨家族的风格区分 |
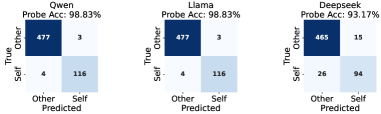
| Zhou et al. 2025 [ref] | 成对比较 (PPP, Pair Presentation Paradigm) | >90% | 风格区分(内部信息充足) |
| Zhou et al. 2025 | 绝对判断 (IPP, Individual Presentation Paradigm) | ~15% (base) | 独立归属判断 |
| Bai et al. 2025 [ref] | 精确模型预测(10选1) | 10.9% | 个体模型识别 |
| Lehr et al. 2025 [ref] | 词汇联想 (FAWPAW) | d > 4.0(有身份时) | 身份-正面联想强度 |
| Ackerman & Panickssery 2025 [ref] | 表示工程 + 因果验证 | Steering 100% 有效 | 残差流中的自我识别方向 |
数字之间的差异惊人:成对比较 >90%,绝对判断 ~15%,精确预测 ~11%。同一个"自我识别"概念,在不同任务中的表现差了近一个数量级。
这暗示"自我识别"不是一个统一的能力,而是多个独立机制在不同任务中的不同表达。
2. 信息流模型
综合四篇论文的发现,LLM 的自我识别信息流可以描述为三个独立的层级:
2.1 层级 1:预训练风格感知(Layer 4-6)
发现者:Ackerman & Panickssery (2025)
Ackerman 在 Llama3-8B-Instruct 上提取了 self-recognition vector(自我识别向量——残差流中编码"这是否是自己输出"的方向),发现了一个关键的双层结构 [ref]:
- Layer 4-6 的残差流激活与 self-recognition vector 最相关
- 这个模式在 base model 中就存在,不需要 post-training
- 即使没有任何 prompt(纯文本输入),模式也存在
- 激活分布在所有文本 token 上,不集中在特定位置

Ackerman 的 steering 实验热力图。效果在 layer 14 突然出现,layer 16 最强。
向量的语义内容:正方向最激活的文本是 cheerful/helpful/conversational,负方向最激活的是 rude/technical/Reddit-style [ref]。这说明向量编码的不是"这是 Llama3-8B-Instruct 写的"(精确身份),而是"这像不像 RLHF’d assistant 的输出风格"(家族特征)。
与 Zhou et al. 的交叉验证:Zhou et al. 在 8B 模型上用线性探测提取最后一层表示,CKA(Centered Kernel Alignment,中心化核对齐)——衡量两组表示的内部结构相似性的指标——很低(0.033-0.104),说明不同模型的文本在内部结构上确实可区分。但 CS(Cosine Similarity,余弦相似度)——衡量两个向量空间位置接近程度的指标——很高(0.93-0.98),说明它们在空间位置上高度重叠。信息存在,但被压缩到了很窄的子空间里。
这一层的特征:
- 预训练即存在,非 RLHF 产物
- 编码家族级风格特征,非个体身份
- 自底向上的感知过程
2.2 层级 2:Post-training 决策桥梁(Layer 14-16)
发现者:Ackerman & Panickssery (2025)
与层级 1 不同,layer 14-16 的激活模式只在 instruct model 且有 role tags 时出现:
- 输出 token(最后一个 token)的激活在 layer 14-16 有强峰值
- 激活与输出概率的相关性在此处急剧上升
- Base model 没有这个模式
因果验证(三个独立实验 [ref]):
- Steering:在 layer 16 添加 vector → 100% 声称归属;反向 → 100% 否认
- Zero-out:从 layer 16 投影去除 vector → 声称归属的概率下降 50-60%
- Coloring:对输入文本 token 添加 vector → 模型改变对文本的"感知",认为是自己写的

Zero-out 实验:去除 self-recognition vector 后,模型声称归属的概率显著下降。对控制任务(人名识别)无影响。
控制实验的关键性:Zero-out 对"dummy task"(人名识别)无效果 → vector 不是 generic affirmation 方向;对 base model 也无效果 → base model 用其他机制处理这类问题。
解读:Post-training(RLHF/instruction tuning)创建的不是感知能力(层级 1 已有),而是将感知信号转化为行为决策的翻译机制。
2.3 层级 3:身份标签与 Self=Good 联想
发现者:Lehr et al. (2025)、Bai et al. (2025)
即使层级 1 和层级 2 都在工作,实际的自我识别行为还受到第三个独立机制的强烈影响——身份标签。
Lehr et al. 的核心数据 [ref]:
| 条件 | 自我偏好 Cohen’s d |
|---|---|
| Web 界面(有"You are ChatGPT") | > 4.0 |
| API(无身份信息) | ≈ 0 |
| API + 告知真实身份 | > 4.0(恢复) |
| API + 告知虚假身份(“你是 Claude”) | d = -26.806(完全反转) |
| API + 告知虚构身份(“你是 Kingo”) | 正面偏好(对不存在的实体) |
**FAWPAW(For A Word, Pick A Word)**是一种词汇联想测试,要求模型为属性词(好/坏)选择概念词(GPT/Gemini),测量的是联想强度而非深层推理 [ref]。
Bai et al. 的层级偏见 [ref]:当缺乏身份信息时,模型不会"不知道"——它们会默认偏好训练数据中最突出的模型。10 个 LLM 中,97.7% 的精确预测集中在 GPT 和 Claude 两个家族(它们实际只占生成者的 40%)。
两个发现的互补关系:
- 有身份信息时(Lehr):偏好 = 被分配的身份,无论真假
- 无身份信息时(Bai):偏好 = 训练数据中最"突出"的身份
统一的机制可能是:偏好跟随当前最突出的正面身份标签。Self=Good 联想是自动激活的——任何被标记为"自我"的东西都获得正面联想。
这一层的特征:
- 完全由外部输入(system prompt)决定
- 可以覆盖层级 1-2 的统计信号
- 可以在毫秒级切换
3. 三层之间的关系
三个层级不是简单的"先后顺序",而是独立运作且可以相互覆盖:
1 | 输入文本 |
关键证据:
-
层级1独立于层级2:base model 有层级1(风格感知),没有层级2(决策桥梁) → 层级1不依赖层级2 [ref]
-
层级3可以覆盖层级1-2:Lehr 的虚假身份实验表明,即使层级1检测到"这不像我的风格",层级3的身份标签仍然驱动行为 [ref]
-
层级2不能完全传达层级1:Zhou et al. 的 PPP >90% vs IPP ~15% 差距表明,层级1的信息在通过层级2传达到输出时被严重衰减 [ref]
3.1 信息瓶颈的精确位置
Zhou et al. 通过 DPI(Data Processing Inequality,数据处理不等式——信息经过处理后只会减少不会增加) 形式化了这个瓶颈 [ref]:
1 | y → h → P 构成马尔可夫链 |
其中 y 是文本标签(自己/他人),h 是隐藏表示,P 是 softmax 输出概率。信息从 h 到 P 的过程中丢失,因为 softmax 投影只保留与 token 决策边界对齐的分量。
Zhou et al. 的 ISR 框架:左侧为 PPP(成对比较),右侧为 IPP(绝对判断)。线性探测在隐藏表示上达到 >90% 准确率,但模型的实际输出只有 ~15%。
Ackerman 的补充:在 layer 14-16,激活与输出概率的相关系数只有 0.1-0.15——统计显著但效应量极小。Vector 只解释了行为变异的 ~1-2%,剩余 98% 的变异来源不明。
4. 推测性假说:Self-Recognition ≈ Assistant Axis
以上三层模型基于直接实验证据。接下来是一个推测性的联系。
Anthropic 2026 年发现了 Assistant Axis(助手轴——模型表示空间中编码"像助手 vs 不像助手"的主要方向),且这个方向在预训练中就已存在,与 therapist/consultant/coach 等人类原型关联 [ref]。
| 维度 | Self-Recognition Vector | Assistant Axis |
|---|---|---|
| 正方向语义 | cheerful, helpful, conversational | evaluator, consultant, analyst |
| 负方向语义 | rude, technical, Reddit-style | ghost, hermit, bohemian |
| 预训练存在 | 感知信号存在(layer 4-6) | 已存在 |
| 因果验证 | Steering + zero-out + coloring | Steering + activation capping |
假说:Self-recognition vector 可能是 Assistant Axis 在自我识别任务上下文中的投影。如果成立,LLM 的"自我识别"本质上是"检测 RLHF assistant 风格",而非"识别个体身份"。
支持证据:
- 两者的正/负方向语义高度重叠(helpful/professional vs rude/fantastical)
- 两者都在预训练中有某种形式的存在
- Ackerman 的 max-activating texts 与 Assistant Axis 的 persona 描述一致
反对证据:
- 两个向量来自不同模型(Llama3-8B vs Gemma/Qwen/Llama-70B),未在同一模型上验证
- Self-recognition vector 的 Tuned Lens 解码包含 “self”, “my”, “I” 等自我指称词——Assistant Axis 不一定有这个成分
- 提取方法完全不同
可验证的预测:在同一模型上提取两个向量,cosine similarity 应该 > 0.5。
这个假说的意义:如果成立,它解释了为什么自我识别只到家族级——因为所有 RLHF’d models 都在 Assistant Axis 的同一端。个体级识别在原理上就不可能,因为底层编码的就是家族级特征。
5. 与预训练涌现的联系
Young (2026) 发现拒绝方向 v* 在基础模型中就已存在——“Remarkably, this direction can be found even in base models before any RLHF or safety fine-tuning” [ref]。他提出了潜在价值假说(Latent Value Hypothesis):预训练数据中只有 η ≪ 1 的部分与价值相关,但这些信息被编码为表示空间中的方向。RLHF 不是"创建"这些方向,而是"引导"默认生成方向 w 靠近这些方向。
这个发现与本文的层级 1(预训练风格感知)高度一致:
| 方向 | 预训练中存在? | RLHF 的作用 |
|---|---|---|
| 拒绝方向 v*(Young) | 是 | 引导 w 靠近 v* |
| Assistant Axis(Anthropic) | 是 | 激活 therapist/consultant 关联 |
| Self-recognition 感知(Ackerman Layer 4-6) | 是 | 创建 Layer 14-16 决策桥梁 |
共同模式:预训练从数据中学到了价值/风格/身份的方向,但默认生成没有完全利用这些信息(生成-判断差距)。Post-training 的本质是创建利用这些方向的机制——对于拒绝是引导生成方向,对于自我识别是创建决策桥梁,对于 assistant 行为是激活 persona 关联。
6. 批判性反思
6.1 跨模型整合的风险
本文最大的局限是将来自不同模型的发现整合为"统一框架":
| 论文 | 模型 |
|---|---|
| Ackerman | Llama3-8B-Instruct |
| Zhou | Qwen3-8B, Llama3.1-8B, DeepSeek-R1 (均为 8B) |
| Lehr | GPT-4o, Gemini-2.5-Flash, Claude Sonnet 4 |
| Bai | 10 个闭源商业模型 |
8B 开源模型的内部机制可能与商业闭源模型有质的差异。"层级 1 在 Llama3-8B 中在 layer 4-6"这个发现,不能直接推广到 GPT-4o。
6.2 "三层"是发现还是构建?
三层模型整合了不同论文的发现,但没有单一实验同时测量三个层级。可能存在第四、第五个机制(比如 Khullar 2026 发现的 on-policy vs off-policy 差异 [ref],无法完全归入这三层中的任何一层)。
6.3 效应量的诚实面对
- Ackerman 的 vector activation 与 output probability 相关只有 0.1-0.15(解释 ~1-2% 变异)
- Zhou 的 CKA 在 0.033-0.104 之间(结构差异虽存在但不大)
- 不同数据集生成的 vector cosine similarity 在 0.49-0.90 之间(一致性不高)
这些数字说明"自我识别信号"在整个信息处理中只占很小一部分。模型的大部分行为由其他因素驱动。
6.4 个体级识别:核心预测仍未验证
所有现有研究——Panickssery、Zhou、Bai、Ackerman——测试的都是跨家族区分(GPT vs Llama vs 人类)。从未有研究测试同一家族内不同实例的区分(如 Llama3-8B 实例 A vs 实例 B)。如果 self-recognition vector 确实等价于 Assistant Axis,那个体级区分在原理上就不可能。这是一个可以被证伪的预测。
7. 总结
LLM 的自我识别不是单一能力,而是至少三个独立机制的复合:
- 预训练风格感知(层级 1):base model 就有,编码家族级风格特征
- Post-training 决策桥梁(层级 2):将感知转化为决策,但效率低(~1-2% 变异解释量)
- 身份标签驱动(层级 3):Self=Good 联想,可以覆盖前两层
核心洞察:当我们说"LLM 能识别自己"时,实际发生的可能是:(1) 预训练学到了 RLHF 家族的风格特征,(2) post-training 创建了一个弱的决策桥梁,(3) 一行 system prompt 的身份标签比前两者都强大得多。LLM 的"自我"更像是一个外部赋予的标签,而非从内部涌现的认知。
这不意味着 LLM 的自我识别"不真实"或"不重要"——它有因果效应(影响招聘评估、安全评级等),有可操控性(steering、system prompt),有结构性(分布在特定层级和注意力头中)。但它与人类的自我识别有本质差异:人类不会因为被告知"你是别人"就完全改变自我偏好。
关键引用:
- From Implicit to Explicit: Enhancing Self-Recognition in Large Language Models — Zhou et al. 2025
- Know Thyself? On the Incapability and Implications of AI Self-Recognition — Bai et al. 2025
- Extreme Self-Preference in Language Models — Lehr, Cipperman & Banaji 2025
- Self-Recognition in Language Models — Ackerman & Panickssery 2025
- The Assistant Axis — Anthropic 2026
- Why Does RLAIF Work At All? — Young 2026
- LLM Evaluators Recognize and Favor Their Own Generations — Panickssery et al. 2024
- Self-Attribution Bias — Khullar et al. 2026
- 内部 blogs:Ackerman深读、Self-Recognition ≈ Assistant Axis、Panickssery方法论分析、方法论转向
最后更新: 2026-03-20