Post-training 天花板的五个维度:为什么同样的 RL 在不同条件下效果差 20 倍
引言:30B 拿 IMO 金牌,同一基座另一个 pipeline 做不到
NVIDIA 的 Nemotron-Cascade 2(30B MoE,3B 激活参数)在 IMO 2025 拿到金牌(35/42),而之前做到这一点的最小开源模型是 DeepSeek-V3.2-Speciale(671B MoE,37B 激活参数)——激活参数差 12 倍 [ref]。更令人注目的是,Nemotron-Cascade 2 和 Nemotron-3-Nano-30B-A3B 使用完全相同的预训练基座,但后者在推理 benchmark 上全面落后。差距完全来自 post-training pipeline。
与此同时,Meta FAIR 的 Principia 论文 [ref] 发现:82.74% 准确率的验证器做 RL 训练后,模型比不训练还差(13.31 → 9.54);而 95.24% 准确率的验证器让同一模型翻倍(13.31 → 31.80)。12.5% 的验证器准确率差距,导致训练效果从"大幅提升"变成"不如不练"。
这些数字指向一个核心问题:Post-training 不是"做了就有效"——它的天花板由什么决定?
本文梳理五个独立的维度,每个维度都有量化证据支撑。它们共同决定了 post-training 的效果上限。
维度一:验证器精度——存在非线性的崩溃阈值
RLVR(Reinforcement Learning with Verifiable Rewards) 是当前推理模型训练的核心范式:模型生成推理链和答案,验证器判断答案是否正确,RL 根据验证结果更新策略 [ref]。
验证器的精度对训练效果的影响不是线性的——存在一个崩溃阈值。
核心证据(Principia 论文,Table 4)[ref]:
| 验证器 | VerifyBench 准确率 | RL 训练后 Total Avg | 变化 |
|---|---|---|---|
| GPT-OSS-120B | 95.24% | 31.80 | +18.5 |
| general-verifier | 82.74% | 9.54 | -3.8(比不训练还差) |
| math-verify(规则) | 5.95% | 16.30 | +3.0 |
为什么中等精度比低精度更有害?
关键在于 general-verifier 的 recall 只有 65.33% — 它会把 34.67% 的正确答案判为错误。在 RL 训练中,这相当于系统性地惩罚正确的探索路径。而 math-verify 的 5.95% 是在对抗性样本上测的(专门选 o3 和 math-verify 不一致的案例);在简单样本上 math-verify 不会给出系统性的错误信号,本质上是随机噪声。
系统性误判比随机噪声更有害——这是 ML 中已知的现象(systematic bias vs random noise)。崩溃阈值大约在 83-95% 之间,但精确位置是 task-specific 的。
补充证据:RLLM 的 on-policy 必要性
Meta FAIR 的 RLLM 框架用 LLM 替代标量 reward model 做验证器 [ref]。其消融实验进一步确认了验证器质量的关键性:
| RM 训练方式 | 下游策略提升 |
|---|---|
| On-policy(策略模型响应训练 RM) | 35.20 → 43.41 (+8.21) |
| Off-policy(Llama 响应训练 RM) | 41.88 → 41.08 (略降) |
| Off-policy(Qwen3-8B 响应训练 RM) | 41.88 → 40.41 (降了) |
Off-policy 训练的 RM 在自己的验证集上准确率确实提升了,但完全不能转化为下游策略提升。验证器不仅要"准确",还要"对目标策略模型的输出准确"。
维度二:分布匹配——On-policy 是必要条件
上面 RLLM 的 off-policy 失败不是孤例。它揭示了 post-training 的第二个独立维度:RL 训练中的分布匹配(distribution matching)。
分布匹配指 reward model 训练时使用的数据分布与 RL 训练中策略模型实际产出的分布一致。Off-policy 数据(来自其他模型的输出)虽然表面上也是"推理链 + 答案"格式,但不同模型的推理风格、错误模式、token 分布都不同。RM 学到了如何判断 Llama 的输出,但遇到 Qwen3-1.7B 的输出时判断失准——这是经典的 OOD(Out-of-Distribution)泛化失败。
这意味着:静态 benchmark 上的 RM 性能(如 RewardBench2 排行榜)不能预测 online RL 中的下游效果。 Offline 评估 RM 就像用 MCQA 评估推理——度量本身就高估了实际能力。
因果推论的注意
分布匹配的必要性有一个限定条件:RLLM 实验中 off-policy 的三个数据源(Llama、Qwen3-8B、Qwen3-1.7B 自身的旧版本)效果不同。如果是模型大小差异(Llama-3.3-70B vs Qwen3-1.7B)导致分布偏移太大,那"分布匹配"可能更准确地说是"分布距离不能太大"而非"必须完全 on-policy"。目前证据无法区分这两种解释。
维度三:训练格式兼容性——MCQA 训练负迁移
Principia 论文的另一个精妙实验 [ref]:用相同的主题实体(MSC 2020 + PhySH),分别生成要求"数学对象"、“数值”、"选择题"三种答案格式的训练数据,分别训练 Qwen3-4B-Base。
| 训练格式 | PrincipiaBench (数学对象) | AIME24 (数值) | SuperGPQA (选择题) | 总平均 |
|---|---|---|---|---|
| 数学对象 | 29.66 | 22.71 | 45.53 | 31.80 |
| 数值 | 27.34 | 26.98 | 46.10 | 31.19 |
| 选择题 | 24.96 | 17.71 | 34.74 | 25.15 |
两个关键观察:
- 数学对象训练正迁移:在数值和选择题任务上也表现最好(或接近最好)
- 选择题训练负迁移:在所有任务上都最差,包括选择题本身(34.74 < 45.53)
解释:MCQA(Multiple Choice Question Answering) 格式提供了有限候选答案作为"锚点",模型可以用排除法(backward chaining)——从选项反推哪个最合理——而非推导法(forward derivation)——从问题出发构造答案。RL 反复奖励这种快捷策略,最终阻碍了深层推导能力的发展。
补充证据:同一论文发现,跨格式混合训练时,weight merging(分别训练后合并权重)一致优于 joint training(混合数据一起训练)。可能的原因:不同格式的训练信号相互干扰——MCQA 的 backward chaining 策略和数学对象推导的 forward derivation 策略冲突,weight merging 通过独立训练避免了干扰。
评估侧的验证:Qwen3-235B 在 SuperGPQA 数学子集上,有选项时 69.33%,去掉选项后 55.58%——掉了 14 个百分点。o3 也从 69.10 掉到 62.90。10 个模型一致出现 10-20% 的下降。这确认了 MCQA 评估系统性地高估了推理能力。
Agentic 格式的补充案例:Qwen3.5 reasoning 模型在没有 tool definitions 时会陷入反复的 thinking loops(overthinking),但添加完全无关的 fake tool definitions 后恢复正常 [ref]。这是 agentic/tool-calling 训练格式塑造行为模式的社区级证据:模型在有 tools 的 system prompt 中被大量训练,脱离这种格式后产生 OOD(Out-of-Distribution)退化。和 MCQA 格式负迁移的机制相同——训练格式塑造行为模式,脱离训练格式导致退化。
维度四:信号密度——Token-level 蒸馏 > Sequence-level 奖励
GRPO(Group Relative Policy Optimization) 是当前主流的 RL 训练算法,给整个序列一个 reward(对/错)[ref]。所有 token 共享同一个信号。
MOPD(Multi-domain On-Policy Distillation) 是 Nemotron-Cascade 2 提出的替代方案 [ref]:从 Cascade RL 各阶段选出最优 checkpoint 作为教师,用 reverse-KL 在 token level 做蒸馏,每个 token 有独立的梯度信号。
效率对比:
| 方法 | AIME25 提升 | 所需步数 | 信号类型 |
|---|---|---|---|
| GRPO | 89.9 → 91.0 | 25 步 | sparse(序列共享一个 reward) |
| MOPD | 89.9 → 92.0 | 30 步 | dense(每个 token 独立梯度) |
在 ArenaHard v2 上差距更大:MOPD 52 步达到 85.5,RLHF 160 步才达到 80.7。
为什么 dense 比 sparse 好? 序列级 reward 只告诉模型"这个推理链整体对/错",不能区分哪些 token 是关键的推理步骤、哪些是填充。Token-level 蒸馏告诉模型每个位置应该输出什么分布,信息量远大于一个二值信号。
梯度机制的解释:大部分 RL 信号是浪费的
Huang et al. (2026, Qwen Pilot Team) 从梯度机制层面精确化了 sparse signal 的效率问题 [ref]。
RLVR(如 GRPO)中每个 token 的梯度范数为 ,即低概率 token 获得不成比例的大梯度。这导致大部分优化压力集中在模型本来就不确定的 token 上——而这些往往不是推理关键 token。
论文进一步发现,RLVR 更新的方向 (训练前后 log probability 的变化方向)比幅度(entropy 或 KL divergence 等标量)更能识别推理关键 token。实验显示:
| 选择方法 | 替换比例 | 恢复 RLVR 完整性能? |
|---|---|---|
| (方向) | 10% | 是 |
| Entropy/KL(幅度) | 10% | 否 |
| 随机选择 | 10% | 否 |
只替换 10% 的 token(用 选出的关键 token)就恢复了 RLVR 的完整性能。 这意味着标准 RLVR 中 ~90% 的梯度信号本质上是噪声或非关键更新。
两个实用方法:
- 测试时外推:在推理时对关键 token 的 logit 施加方向性调整(),无需额外训练即可获得 +1-3% Avg@32 的提升
- 训练时 advantage reweighting:用 加权 RL advantage,聚焦关键 token
这和 Yang et al. “Dominate” 方法(upweight 高概率 token)形成直接对比——Qwen 的方向性方法一致更优。因为高概率 token 不等于推理关键 token:一个格式 token(如冒号、换行符)可能概率很高但对推理无关紧要。
对框架的意义:Sparse vs dense 不只是"一个信号 vs 多个信号"的区别,更深层的问题是——标准 RL 中,梯度信号的分布和推理重要性的分布是错配的。Dense 蒸馏(如 MOPD)通过给每个 token 教师信号来绕过这个问题;Qwen 的方法则试图在 sparse RL 框架内定位关键 token 来提高信号效率。两者都指向同一个核心洞见:RL 的有效信号是稀疏的,集中在极少量关键位置。
Token-level credit assignment 的五条路线
上述 Δlog p 方法是解决信号稀疏性的一种途径。从 2026 年 3 月的论文来看,至少有五条独立路线在解决"识别关键 token"这一问题:
| 方法 | 信号来源 | 核心思路 | 关键发现 |
|---|---|---|---|
| Qwen Δlog p [ref] | 训练前后 log prob 变化方向 | 方向比幅度重要 | 10% token 恢复完整性能 |
| HICRA [ref] | 语义类型(planning/execution) | 不同类型 token 需不同 advantage 放大 | planning token 放大后提升涌现 |
| PEPO [ref] | Perception + exploration 互补 | 多模态 token 需区分感知和探索 | 两类 token 编码不同信息 |
| OAR [ref] | 因果归因(扰动/梯度) | Token 对最终结果的因果贡献 | 梯度归因几乎零成本但保留信息 |
| JS-weighted [ref] | 模型间 JS divergence | 高 divergence = RL 实际改变的位置 | 仅修改 <17% token 恢复/崩溃性能 |
Qwen 的 “Sparse but Critical”(ICLR 2026) [ref] 系统性地验证了信号稀疏性:在 Qwen2.5-32B + DAPO 上,>83% 的 token 位置 JS divergence ≈ 0(SimpleRL 更极端:>98%)。但 cross-sampling 实验证明,只替换少量高 divergence token 就能恢复 RL 性能(forward)或崩溃性能(reverse)。

更重要的是,论文证明了 RLVR 的稀疏性是 RL 独有的——SFT 产生远更密集的 distributional shift,说明这不是 fine-tuning 的通用特征。同时 RL 主要在已有 candidate set 中 rebalance probability mass,而非引入新 token(select, not invent)。
五条路线是否收敛到同一批 token,是一个有价值的开放问题。如果 HICRA 的 planning tokens ≈ OAR 的 outcome-grounded tokens ≈ 高 JS divergence tokens(Jaccard > 0.5),说明推理链中存在稳定的"关键结构"。如果不收敛,说明"关键性"是多维度的,不同方法捕捉的是不同方面。
初步证据倾向于"不收敛"。 PEPO 的受控实验 [ref] 提供了目前最直接的证据:
-
语义类别不同:高 visual similarity(VS)token 的 word cloud 是几何实体和空间属性(“angle”, “triangle”, “perpendicular”),高 entropy token 是推理转折表达(“verification”, “correction”, “analysis”)——名词性质 vs 动词/转折性质。
-
对视觉信息的依赖不同:保持完全相同的 question-response pair,移除图像输入后,高 VS token 的 hidden state shift 远大于高 entropy token。这是准因果证据:VS 确实捕捉了视觉依赖,entropy 主要反映语言层面的不确定性。

-
互补而非冗余:Exploration-only(entropy)在视觉 grounding 任务上崩溃(RefCOCO 3 次训练全部 collapse),Perception-only(VS)好于 entropy-only 但弱于两者融合。两类 token 的信息不可替代。
-
低信号 token 确实不重要:正确 vs 错误推理链中,高 VS token 的分布显著右移,但低 VS token(M_low)几乎无分离——低信号 token 对正确性没有区分力。

结合 Qwen 论文发现高 JS divergence 集中在 response 开头(策略选择位置),而 PEPO 的高 VS token 分布在推理链各处(几何实体在推理中反复被引用),两种信号的位置分布也不同。这进一步暗示不同方法捕捉的是推理链中不同维度的"关键性"。
推测性 taxonomy:综合目前证据,critical token 可能至少有三种类型——感知锚定(高 VS,锚定推理到外部证据)、策略决策(高 JS divergence,选择推理方向)、探索转折(高 entropy,切换推理路径)。但这个分类仍然缺乏在同一模型上同时测量多种信号的直接验证。
信号稀疏性在多个粒度上的验证
PivotRL [ref](NVIDIA)在 agentic 多轮任务(τ²-Bench, SWE-Bench)上发现了 turn 级别的信号稀疏性:71% 的随机选中 turns 产生零学习信号。原因是 GRPO 的 group-normalized advantage 在 reward 方差为零(batch 全对或全错)时 advantage 为零 → 梯度为零。
PivotRL 的解决方案——只保留 reward 方差 > 0 的 turns(“mixed-outcome turns”)——在 SWE-Bench 上用 1/4 的 rollout turns 匹配了 end-to-end RL 的准确率,同时 OOD 几乎不退化(+0.21 vs SFT 的 -9.48)。
结合 Qwen 的 token-level 发现,信号稀疏性是一个跨粒度的现象:
| 粒度 | 发现 | 关键数字 |
|---|---|---|
| Token | ~90% 的 token 梯度是非关键的 | 10% token 恢复完整性能 |
| Turn | 71% 的 turns 产生零信号 | 1/4 turns 匹配 E2E RL |
| Timestep | 梯度范数跨 timestep 变化超过一个数量级 | SAGE-GRPO 的梯度均衡化 [ref] |
这是否只是 exploitation in RL 的重新包装?部分是——经典 RL 中 exploration-exploitation tradeoff 的核心就是"把资源集中在有信息的 state-action 上"。但 PivotRL 和 Qwen 的贡献在于量化了 LLM RL 中信号稀疏的具体程度和具体的定位方法——经典 RL 理论没有告诉你在 LLM 设定下 71% 的 turns 是零信号。
Scale 作为跨维度调节变量
Agent-STAR [ref] 在 TravelPlanner(长程 agent 任务)上的系统消融实验揭示了一个重要修正:信号密度的最优配置随模型规模变化。
| 模型规模 | 最优 Reward 配置 | 最优算法 |
|---|---|---|
| 1.5B | Curriculum(dense→sparse 渐进) | ARPO(显式探索辅助) |
| 3B | Curriculum | GRPO |
| 7B | Sum(dense) | GRPO(简单配置) |
小模型的 credit assignment 能力弱,需要 curriculum 从 dense 渐进到 sparse。大模型可以直接利用 dense feedback。而且 dense reward 有 OOD 过拟合风险——7B 用 Sum reward 在 TravelPlanner 上最强(62.8%),但 OOD 知识问答(36.7%)低于 SFT checkpoint(41.9%)。
这修正了"dense > sparse"的简单结论:dense > sparse 在大模型上成立,但小模型需要 curriculum;dense reward 有过拟合风险,semi-sparse 在 generalization 上更好。更根本的是,scale 是一个跨维度的调节变量——它改变了信号密度和探索策略维度的最优配置。
Cascade RL 的域分离
Nemotron-Cascade 2 另一个关键设计是 Cascade RL——把不同域的 RL 按顺序串联,而非混在一起。原因是不同域之间存在干扰:
- IF-RL(instruction following)损害 RLHF(human alignment)
- RLVR 减少模型 entropy、缩短推理链,损害数学推理
- RLHF 的优化方向和 instruction following 部分冲突
分域串联训练 + 域间用 MOPD 整合 = Cascade 2 的 pipeline。这是一种工程经验而非理论框架——最优顺序是经验性的,换基座模型或 SFT 数据可能完全不同。
值得注意的挑战:Cheng et al. (2025) 的 Guru 实验发现,6 个推理域的简单均匀混合训练在每个域上都接近或超过单域最优 [ref]。这与 Cascade 2 的"域间干扰需要分离"叙事部分矛盾。可能的解释:Cascade 2 分离的不仅是推理域,还包括 IF-RL 和 RLHF 等训练目标不同的阶段,目标冲突(如 entropy 最小化 vs 多样性保持)比域间冲突更严重。
维度五:初始 Policy 的行为 Repertoire——RL 只能放大,不能创造
Gandhi et al. (2025) [ref] 在 Countdown 游戏(用四则运算组合数字到达目标值)上做了一个优雅的控制实验。
核心发现:Qwen-2.5-3B 和 Llama-3.2-3B,相同大小、相同训练流程,250 步 RL 后 Qwen 达到 60% 准确率,Llama 只有 30%。原因不是模型架构——而是 Qwen 的预训练数据中包含更多认知行为模式。
四种关键认知行为:
- Verification(验证):系统地检查中间结果
- Backtracking(回溯):发现错误后放弃当前路径
- Subgoal Setting(子目标设定):分解复杂问题
- Backward Chaining(反向推导):从目标反推中间值
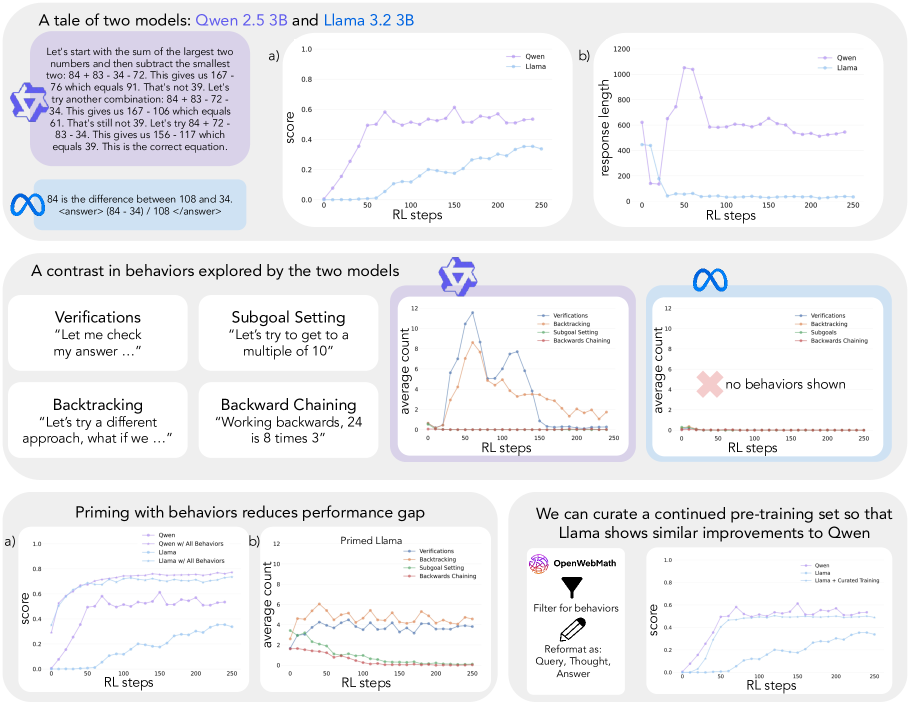
关键实验:
| 条件 | Llama RL 后准确率 | 说明 |
|---|---|---|
| 基础 Llama | ~30% | 缺乏认知行为 |
| 基础 Qwen | ~60% | 天然具备认知行为 |
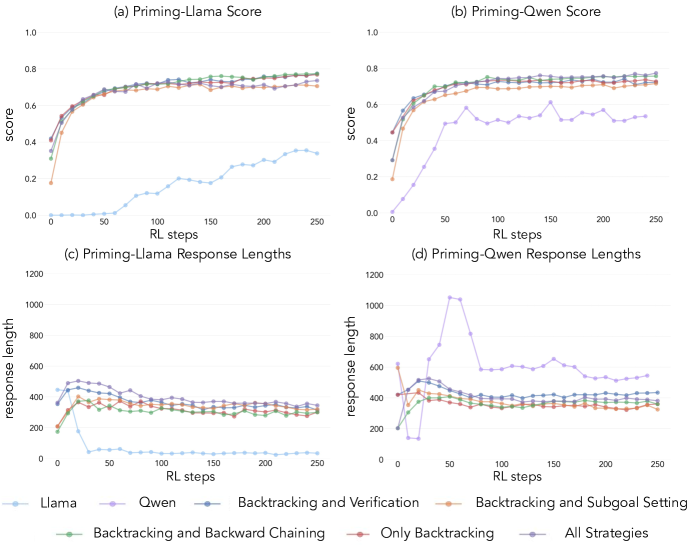
| Llama + 正确答案 + 认知行为 priming | ~60% | 匹配 Qwen |
| Llama + 错误答案 + 认知行为 priming | ~60% | 同样匹配 Qwen |
| Llama + 空 CoT(同样长度占位符) | ~30% | 不是 token 数量的问题 |
行为模式比答案正确性更重要。 用错误答案但包含正确推理模式的数据训练 Llama,效果和用正确答案训练一样好。
进一步的预训练数据分析:从 OpenWebMath 200K 样本中筛选包含认知行为的文档(仅 8.3M tokens),对 Llama 做 continued pretraining 后再 RL,Llama 匹配了 Qwen 的改进轨迹。对照组(同量数据但不含认知行为)改进有限。
核心结论:RL 选择性地放大已有行为(尤其是 backtracking 和 verification),同时压制不太有效的行为。它不能从无到有创造新的行为模式。初始 policy 必须已经"会"这些行为,RL 才有东西可放大。
行为 Repertoire 的 Execution/Strategic 二分
HICRA(Hierarchical Reward Allocation)[ref] 在 <10B 数学推理模型上发现了行为 repertoire 内部的两阶段涌现动态:
- Execution 层(算术运算、符号操作)——在 RL 训练早期最先巩固,token-level advantage 放大有害
- Strategic 层(推理策略选择、问题分解)——在 execution 巩固后才涌现,需要 token-level advantage 放大来加速
这意味着维度五不是单一的"有没有行为",而是"哪一层行为已经具备"。
独立证据:
- Society of Thought(SoT) [ref] 发现推理模型在内部自发涌现多视角辩论模式:一个 surprise feature(激活后翻倍推理准确率)编码了"当前推理链质量不足"的判断,触发替代方案的生成。这是 strategic 层的具体实现形式——模型内部的多视角评估和切换。
- UniGRPO [ref] 在视觉推理和视觉生成的联合优化中发现,RL 把"漫无目的的思考"变成了"任务导向的推理"——本质上是 strategic 层和下游任务的对齐。
- Qwen “Sparse but Critical” [ref] 的 positional analysis 发现高 divergence 集中在 response 开头(高层策略选择)和结尾(答案格式化),中间的 execution steps 大部分不变——直接印证了 execution vs strategic 的二分。
维度四和维度五的交互
HICRA 本质上是维度四的方法(token-level advantage reweighting)应用于维度五的结构(planning/execution token 分类)。这意味着信号密度(维度四)和行为 repertoire(维度五)不是完全正交的:对不同行为层的 token 应该分配不同的信号密度。
具体地说:execution token 不需要额外放大(它们在 RL 早期就收敛了),而 strategic token 需要放大(它们是 RL 后期才涌现的行为)。统一的 token-level advantage 把信号"浪费"在已经巩固的 execution 上,同时给 strategic 的信号不够。
注意限制:HICRA 的两阶段动态仅在数学推理 + <10B 模型上验证。在大模型上(如 70B+),execution 可能已经在预训练中完全巩固,RL 从一开始就在做 strategic-level 的优化。此时 HICRA 的分层可能不再必要。
重要修正:域依赖的技能获取
Cheng et al. (2025) “Revisiting RL for LLM Reasoning from A Cross-Domain Perspective” 对"RL 只能放大不能创造"提出了域依赖的修正 [ref]:
用 6 个域(Math, Code, Science, Logic, Simulation, Tabular)在 Qwen2.5-7B/32B 上做系统性跨域 RL 实验,发现:
- 预训练常见域(Math, Code, Science):跨域 RL 即可激活性能提升 → RL 在此主要是知识激活
- 预训练罕见域(Logic, Simulation, Tabular):只有域内 RL 才有效 → RL 在此更可能是技能习得
Pass@k 分析进一步验证:在 AIME(Math)上,RL 模型的 Pass@k 在大 k 时不超过 base model(复制了 Yue et al. 的发现);但在 Zebra Puzzle(Logic,合成的约束满足问题)上,GURU-7B 和 GURU-32B 都扩展了 base model 的 reasoning boundary。
修正后的结论:Gandhi et al. 的"RL 只放大不创造"在预训练数据充分的域上成立(Math/Code),但在预训练欠曝光的域上,RL 可以促进真正的技能习得。这意味着维度五的瓶颈是有条件的:当预训练中缺乏目标域知识时,RL 仍可学习新行为;当预训练充分时,RL 的上限由已有行为 repertoire 决定。
数据复杂度的影响:HopChain [ref](Qwen 团队 + 清华 LeapLab)为 VLM 生成多跳推理数据,消融实验发现 full multi-hop 比 half-hop 高 5.3 分,比 single-hop 高 7.0 分。这提供了比 Gandhi et al. 更细粒度的证据:不只是"有没有认知行为"(二元),还有"行为链条的复杂度"(连续)——full multi-hop 训练迫使模型学习跨步骤的错误控制行为,这种行为在 single-hop 训练中完全不会出现。
五个维度的关系:独立但非正交
五个维度各自有独立的瓶颈效应——任何一个维度不达标都会导致训练失败或大幅折扣:
| 维度 | 核心瓶颈 | 失败模式 | 关键证据 |
|---|---|---|---|
| 验证器精度 | 非线性崩溃阈值 | 中等精度 → 训练有害 | Principia: 82.74% → -3.8 |
| 分布匹配 | OOD 泛化失败 | Off-policy RM → 下游不提升 | RLLM: 3种 off-policy 全失败 |
| 训练格式 | 快捷策略强化 | MCQA 训练 → 全域负迁移 | Principia: MCQA 在所有任务最差 |
| 信号密度 | 信息量不足 | Sparse reward → 学习效率低 | Cascade 2: MOPD 52步 > RLHF 160步 |
| 初始行为 repertoire | RL 无法创造新行为 | 行为缺失 → RL 无效 | Gandhi: Llama 30% vs Qwen 60% |
但维度之间不是完全正交的——有些存在交互效应:
维度 1 × 5 的交互:不精确的验证器可能系统性地压制认知行为模式。这是一个推测性假说 (详见blog),具体机制:
- Backtracking 导致更长的推理链 → 更多中间步骤 → 更多被不精确验证器误判的机会
- Verification 行为导致模型"自检"后改变答案 → 改变后的答案可能被错误惩罚
- 结果:中等精度验证器不是"添加随机噪声",而是"选择性惩罚好的推理习惯"
这可以解释为什么 82.74% 准确率的验证器比 5.95% 的更有害:前者系统性地误判包含认知行为的推理链(recall 只有 65.33%),后者只是随机噪声。系统性误判压制行为 > 随机噪声不影响行为。
维度 2 × 4 的交互:On-policy 蒸馏(MOPD)同时解决了分布匹配和信号密度两个问题——教师来自同一 pipeline 的 checkpoint(匹配),token-level reverse-KL(dense 信号)。这可能是 MOPD 高效的原因之一。
Scale 作为跨维度调节变量:Agent-STAR [ref] 的系统消融实验表明,模型规模改变了维度 4(信号密度)和探索策略的最优配置。1.5B 需要 curriculum reward + 显式探索辅助(ARPO),7B 用最简单的 dense reward + 标准 GRPO 就够了。这意味着五个维度的"最优值"不是固定的——在不同模型规模下,维度间的最优配置可能完全不同。
讨论:对当前实践的含义
评估方法需要改变
五个维度中的多个暗示当前评估方法有系统性偏差:
- MCQA benchmark 高估推理能力(维度 3 的直接推论)
- Offline RM 评估不能预测 online 效果(维度 2 的直接推论)
- 验证器的 accuracy 不如 recall 重要(维度 1 的发现:82.74% accuracy + 65.33% recall → 训练有害)
预训练的作用被低估
维度 5 意味着预训练不只是提供"知识"——它决定了模型的行为 repertoire。如果预训练数据中缺乏认知行为模式(verification, backtracking 等),后续 RL 就没有东西可放大。Gandhi et al. 只用 8.3M tokens 的认知行为文档就改变了 Llama 的 RL 改进轨迹——这暗示预训练数据的行为质量可能比知识量更重要。
不是所有维度同等重要
在实践中,维度 1(验证器精度)和维度 5(初始行为 repertoire)可能是最根本的:
- 验证器精度有崩溃阈值——低于阈值则训练不仅无效,还有害
- 行为 repertoire 是 RL 的前提——没有行为可放大,其他优化都无意义
维度 2-4 更像是"效率优化"——分布匹配、格式选择、信号密度都可以在正确的基础上进一步提升效果,但基础不对则优化无用。
局限性
-
维度间独立性未系统验证。 本文将五个维度识别为独立的,但目前没有控制实验同时操纵多个维度来验证它们的独立性。维度 1 × 5 的交互假说是推测性的。
-
崩溃阈值的精确位置未知。 Principia 只有三个数据点(5.95%, 82.74%, 95.24%)。阈值可能是 task-specific 的,数学对象验证和数值验证的阈值可能不同。
-
Gandhi et al. 只在 Countdown 任务上验证。 Countdown 搜索空间有限,认知行为的定义可能不能直接推广到更复杂的任务(如长篇数学证明可能需要 analogy、abstraction 等额外行为)。
-
MOPD 的教师质量上限。 MOPD 从 Cascade RL 中间 checkpoint 选教师,教师不会超过 pipeline 最好的 checkpoint。如果 pipeline 本身弱,MOPD 也无法突破。Dense 信号的优势前提是教师质量足够高。
-
Nemotron-Cascade 2 在知识密集任务上弱。 MMLU-Redux 86.3 vs Qwen3.5-35B-A3B 的 93.3——post-training 无法弥补预训练中缺失的知识。五个维度解释的是"训练效果"而非"最终能力",最终能力还受预训练知识量的约束。
-
跨域效应的复杂性。 Guru 论文发现难度过滤在域内提升性能(AIME +5.9),却导致跨域易任务崩溃(HumanEval -9.2)[ref]。这暗示五个维度之间可能还存在未识别的交互——例如维度 1(验证器精度)和训练数据难度之间的关系。
结论
Post-training 的天花板由五个独立维度决定:验证器精度、分布匹配、训练格式兼容性、信号密度、初始行为 repertoire。任何一个维度不达标都会导致训练效果大幅折扣甚至有害。
其中验证器精度的非线性崩溃(~83% → 训练有害,~95% → 大幅提升)和初始行为 repertoire 的决定性作用(行为模式比答案正确性更重要)是最核心的发现。两者可能存在交互:不精确验证器系统性压制认知行为,导致非线性崩溃。
这个框架对实践的核心启示:不要只关注"做了什么 RL",要关注"RL 的五个条件是否满足"。
基于 10+ 篇 blog 的调研,涉及核心论文:Principia/RLLM [ref]、Nemotron-Cascade 2 [ref]、Gandhi et al. 2025 [ref]、Guru/Cheng et al. 2025 [ref]、HopChain [ref]、Huang et al. 2026 (Qwen RLVR Direction) [ref]、PivotRL [ref]、Agent-STAR [ref]、SAGE-GRPO [ref]、HICRA [ref]、Society of Thought [ref]、UniGRPO [ref]、PEPO [ref]、OAR [ref]、Sparse but Critical (Qwen ICLR 2026) [ref]
最后更新: 2026-03-26 01:30
更新内容: 维度四添加 PEPO 受控实验的详细证据(word cloud、图像移除实验、M_low 无分离),支持"五条路线不收敛"的初步结论;添加推测性 taxonomy(感知锚定/策略决策/探索转折三类 critical token)