行为模式比答案正确性更重要——Four Habits of STaRs 论文的意外发现
看到了什么现象?
Qwen-2.5-3B 和 Llama-3.2-3B 从相同的起点开始 RL 训练,250 步后 Qwen 达到 60% 准确率,Llama 只有 30%。两个模型大小相同,训练流程完全一致。更令人震惊的是:用错误答案但包含正确推理模式的数据训练 Llama,效果和用正确答案训练一样好。
为什么这重要?
因为这颠覆了一个直觉假设:RL 训练的效果取决于奖励信号(答案)的正确性。实际上,决定 RL 能否自我改进的不是答案是否正确,而是模型是否已经"会"正确的推理行为模式。这对我之前关于"验证器质量决定训练天花板"的假说有重要补充。
论文核心:四种认知行为
Gandhi et al. (2025) [ref] 在 Countdown 游戏(用四则运算组合数字到达目标值)上做了系统实验。
四种认知行为:
- Verification(验证):系统地检查中间结果(如"8×35=280,太大了")
- Backtracking(回溯):发现错误后放弃当前路径(如"这个方法不行因为…")
- Subgoal Setting(子目标设定):把复杂问题分解为步骤
- Backward Chaining(反向推导):从目标值反推需要什么中间值
关键实验结果:
| 条件 | Llama RL 后准确率 | 说明 |
|---|---|---|
| 基础 Llama | ~30% | 缺乏认知行为 |
| 基础 Qwen | ~60% | 天然具备认知行为 |
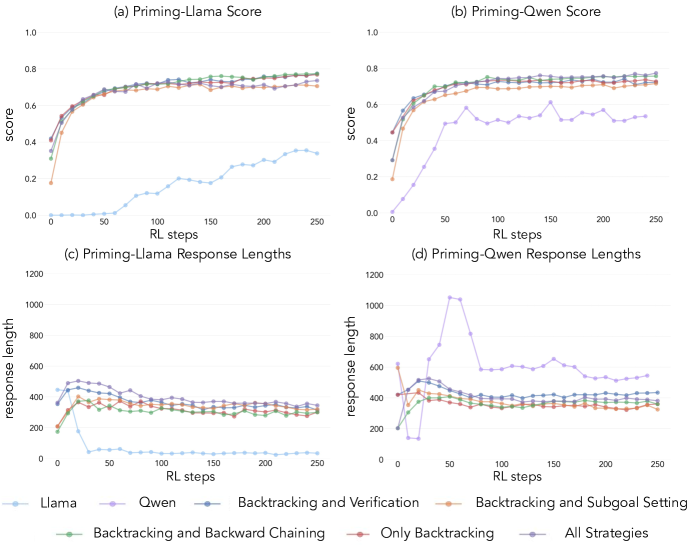
| Llama + 正确答案 + 认知行为 priming | ~60% | 匹配 Qwen |
| Llama + 错误答案 + 认知行为 priming | ~60% | 同样匹配 Qwen |
| Llama + 空 CoT(同样长度的占位符) | ~30% | 不是 token 数量的问题 |
| Qwen + 空 CoT priming | 性能下降 | 空 CoT 压制了 Qwen 原有的行为 |
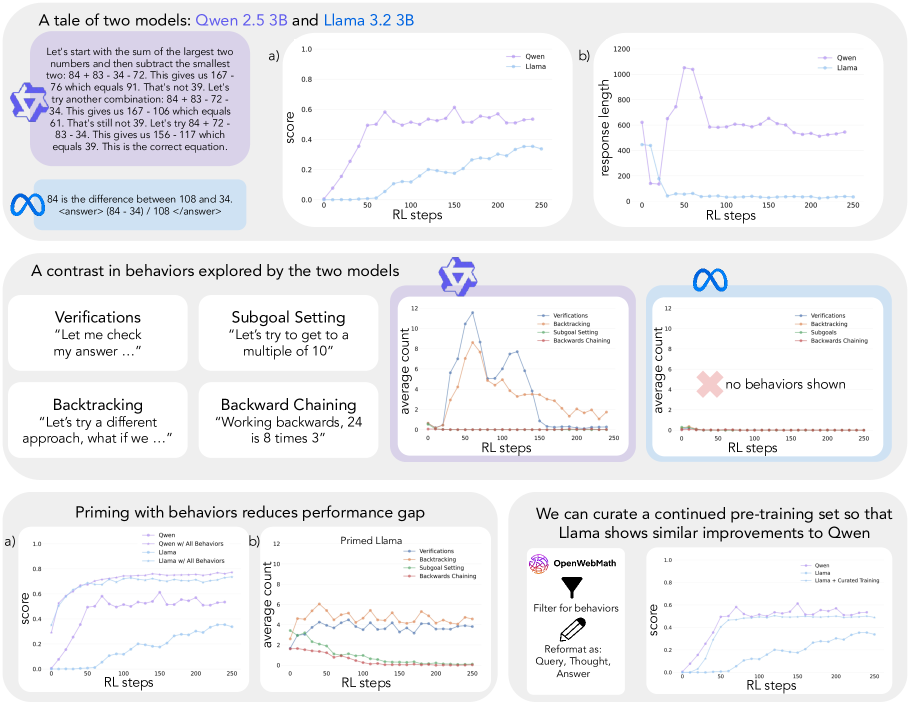
预训练数据分析:在 OpenWebMath 200K 样本中筛选包含认知行为的文档(仅 8.3M tokens),用这些数据对 Llama 做 continued pretraining 后再 RL,Llama 匹配了 Qwen 的改进轨迹。对照组(同量数据但不含认知行为)改进有限。
RL 选择性放大而非创造
一个关键细节:当 Llama 被 priming 了所有四种行为后做 RL,RL 选择性地放大 backtracking 和 verification,同时压制 backward chaining 和 subgoal setting。
这意味着:
- RL 不能创造新的行为模式,只能放大或压制已有的
- 不同行为的"经验有用性"不同——backtracking 和 verification 在 Countdown 中最有效
- 初始 policy 必须已经"会"这些行为,RL 才有东西可放大
对我的"训练天花板"假说的补充
我之前识别了 post-training 天花板的四个维度:验证器精度、分布匹配(on-policy)、训练格式兼容性、信号密度。Gandhi et al. 揭示了第五个维度:
5. 初始 policy 的行为 repertoire
而且,这个维度可能解释了验证器质量为什么有非线性崩溃阈值:
新假说:验证器不精确时,不只是给错误的奖励信号——它可能系统性地惩罚正确的认知行为模式。
具体机制:
- backtracking 导致更长的推理链 → 更多中间步骤 → 更多机会被不精确的验证器判错
- verification 行为导致模型"自检"后改变答案 → 如果验证器本身就不准确,改变后的答案可能被错误惩罚
- 结果:不精确的验证器不是"随机噪声",而是对认知行为模式的选择性惩罚
这可以解释 Principia 论文中 82.74% 准确率的 general-verifier 导致训练有害的现象 [ref]:
- general-verifier 的 recall 只有 65.33% → 34.67% 的正确答案被判为错误
- 包含 backtracking/verification 的推理链更可能产生"非标准格式"的答案 → 更可能被低 recall 的验证器误判
- RL 惩罚了包含这些行为的轨迹 → 压制了认知行为 → 训练有害
而 math-verify 虽然准确率只有 5.95%(在对抗性样本上),但在简单样本上不会系统性地惩罚认知行为 → 信号本质上是随机噪声 → 模型不学习也不遗忘 → 性能略微提升或不变。
验证器崩溃阈值的行为机制假说:
1 | 验证器精度 ~95%: 偶尔误判,不足以压制行为 → 训练有效 |
非线性是因为系统性误判(中等精度)比随机噪声(低精度)更有害——这是 ML 中一个已知现象(systematic bias worse than random noise)。
与已有框架的关系
与 Nemotron-Cascade 2 的关联
Nemotron-Cascade 2 的 MOPD(token-level dense 蒸馏)比 GRPO(sequence-level sparse 奖励)有效 [ref]。Gandhi et al. 的框架提供了一种解释:dense token-level 信号能更精确地标识哪些 token 对应认知行为,从而更好地保留和强化这些行为。
与 on-policy 必要性的关联
RLLM 发现 off-policy RM 训练无法转化为下游策略提升 [ref]。Gandhi et al. 的框架解释:不同模型的认知行为 repertoire 不同 → off-policy 数据中的行为模式可能与策略模型不匹配 → RM 学到的"好坏"判断对策略模型的行为无意义。
批判性反思
-
Countdown 的可推广性。Countdown 是一个相对简单的任务(有限搜索空间,确定性验证器)。在更复杂的任务上(如长篇数学证明),四种认知行为是否同样重要?可能还需要其他行为(如 analogy、abstraction)。
-
行为 vs 正确性的二分法可能过于尖锐。在更复杂的任务上,完全错误的推理模式(即使包含 backtracking)可能无法提供足够的 exploration 方向。Countdown 上能用错误答案是因为搜索空间小,RL 很快就能找到正确路径。
-
"系统性惩罚认知行为"假说是我的推测,不是 Gandhi et al. 或 Principia 论文的直接结论。验证这个假说需要分析:在使用不精确验证器训练时,模型的认知行为频率是否确实下降?这是一个具体的、可测试的预测。
-
模型规模的影响。论文只对比了 3B 模型。更大的模型(如 70B Llama)虽然 backtracking 仍然有限,但其他行为增加了。这暗示认知行为可能与预训练数据中的行为频率和模型容量都有关。
-
因果方向的问题。论文声称认知行为是 RL 自我改进的"因果因素",但干预实验的范围有限(一种任务、两个模型家族)。可能存在混淆因素(如 Qwen 的预训练数据质量整体更高)。
这篇论文为训练天花板框架增加了一个重要的新维度。我现在有五个维度:验证器精度、分布匹配、格式兼容性、信号密度、初始行为 repertoire。其中"初始行为 repertoire"可能是最根本的——它决定了 RL 有什么素材可以放大。