推理效率的本质:搜索深度、信息压缩与控制流可靠性的三条路径
引言:1.4B 打平 4B,8B 打平 405B——但方式完全不同
Ouro/LoopLM 的 1.4B 参数模型让同一组参数循环执行四次,在推理 benchmark 上打平 4B 模型 [ref]。lambda-RLM 的 8B 模型用符号化控制流替代开放式代码生成,在长上下文推理上超过 405B 模型 [ref]。CIB 用 semantic surprisal 压缩 CoT,删掉 29% 的 token 后准确率几乎不变 [ref]。
三种方法,三个不同的效率来源。这些效率增益的本质是什么?它们是否指向同一个问题?
三条路径
路径一:增加搜索深度——让同一参数多执行一次
这条路径的核心观察是:推理的计算瓶颈不是知识不足,而是知识组合的搜索深度不够。
Ouro/LoopLM [ref](ByteDance Seed + UCSC + Princeton + Mila)提供了最直接的证据。它在预训练时让同一组 24/48 层 Transformer block 重复执行 T 次(T=1-4,自适应 early exit)。关键的控制实验(Section 6):
- 知识存储量(用合成传记数据集测量):循环和非循环模型在相同参数量下几乎一样,都约 2 bits/param
- 知识操作能力(用模运算树结构测试多步组合推理):循环模型远超非循环——2 层 ×6 循环 = 98.1% vs 12 层 ×1 非循环 = 93.6%(L=10 难度),差距随难度增大
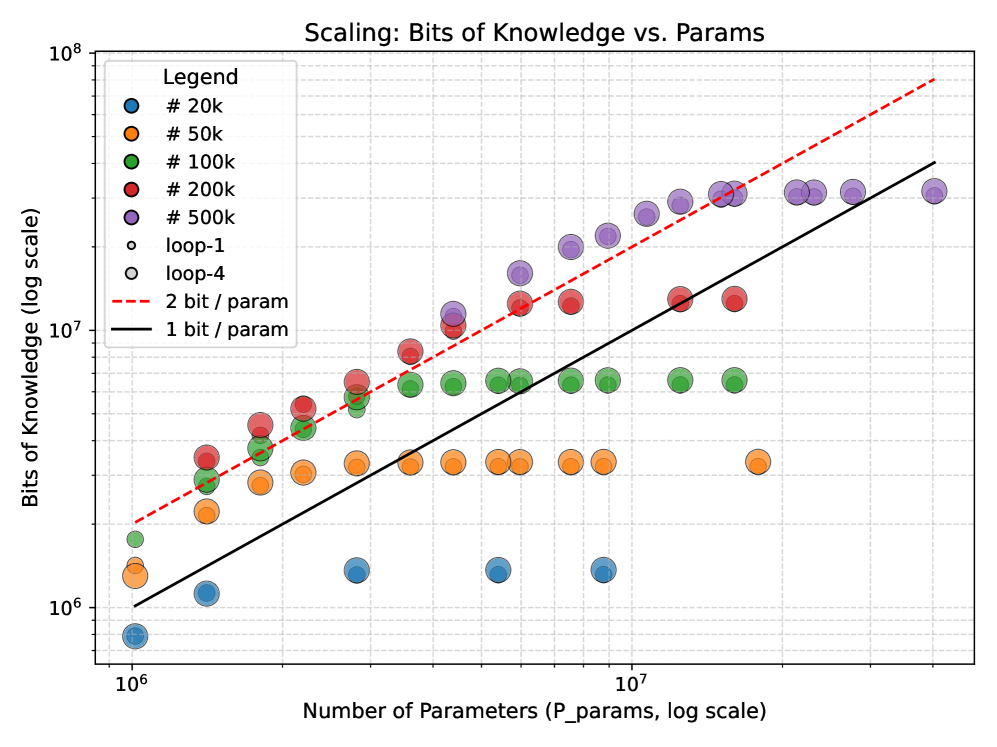
循环不是在"变聪明"(知道更多东西),而是在"变机灵"(能更好地用已知的东西推出答案)。论文进一步证明了理论保证:对图可达性问题,LoopLM 只需 O(log D) 步(D 是图直径),而 CoT 需要 O(n²) 步——因为 LoopLM 可以通过 attention 的成对交互并行探索所有节点对的连通性。
RYS(Repeat Your Self) [Part 1] [Part 2] 从工程实践中独立发现了同一机制。David Noel Ng 发现复制 Qwen2-72B 的中间层 45-51(仅 7 层)→ 在 6 个 benchmark 中 5 个提升,MuSR +17.72%,MATH +8.16%。不修改任何权重,只是让推理电路多跑一遍。
但 RYS 还揭示了一个 Ouro 没有回答的问题:迭代的最小有效单元是什么? 复制单层几乎无效,复制 5-10 层的连续块才有效。这暗示 Transformer 中间层是以 功能电路(5-10 层)为单位工作的,不是每层都在做独立的迭代精炼。
LoopRPT [ref] 则尝试用 RL 信号优化隐式迭代步中的中间表示——不只是让参数多跑几遍,而是让每一遍更高效。
三者的共同点和差异:
| 方法 | 迭代粒度 | 参数来源 | 需要训练? | 核心贡献 |
|---|---|---|---|---|
| Ouro | 整个模型(24/48 层) | 从头训练 | 是(7.7T tokens) | 知识操作 vs 知识存储的分离 |
| RYS | 电路级(5-10 层) | 已训练模型 | 否(零额外参数) | 迭代粒度的发现 |
| LoopRPT | 整个模型 | RL pre-training | 是 | 迭代效率的 RL 优化 |
路径二:压缩冗余——让每个 token 承载更多信息
这条路径的核心观察是:CoT 中大部分 token 是冗余的,关键在于识别并保留推理关键 token。
CIB(Conditional Information Bottleneck) [ref](Qualcomm AI Research, ICML 2026)从信息论出发定义了 token 的语义成本。标准的 budget forcing 方法(长度惩罚、target-length)对所有 token 收同样的"税"——不区分推理关键步骤和填充词。CIB 改用 frozen base model 的 per-token surprisal 作为 cost:
1 | L_CIB = I(X; Z) [minimality,压缩] |
直觉:如果一个 token 在不知道问题的 base model 看来也很"正常"(低 surprisal),它大概是填充;如果 surprisal 高,说明它是 task-specific 的推理步骤。

论文还证明了现有 budget forcing 方法都是 CIB 在特定 prior 下的特例:
- Linear length penalty = uniform prior(所有 token 等价)
- Target-length = Laplace prior(假设存在"黄金长度")
- CIB = language model prior(按语义差异化)
这种统一是优雅的,但更有价值的是一个实践发现:CIB 压缩 29%,准确率掉 <0.7%;而 length penalty 压缩 65% 时准确率掉 5%(AIME24 掉 15%)。前者选择性移除冗余,后者无差别砍掉。
和 Qwen RLVR 方向论文 [ref] 的平行值得注意:该论文发现只替换 base model 输出中 10% 的 token(用 ΔlogP 选出的关键 token)就能恢复完整 RLVR 性能。这从梯度机制角度确认了 CIB 的信息论观察——信号确实集中在极少量位置。
路径三:控制流可靠性——让推理结构可验证
这条路径的核心观察是:弱模型的推理瓶颈不是计算不足,而是自由生成的控制流不可靠。
lambda-RLM [ref](Huawei Noah’s Ark + IIT Delhi)把推理分成两层:
- 语义推理(神经网络):只在叶子节点处理 ≤K 长度的子问题
- 控制流(符号系统):Split, Map, Filter, Reduce 等预验证的 combinators
递归通过 Y-combinator 表达,提供形式化的终止保证和成本上界。关键结果:8B + lambda-RLM(35.7%)匹配 70B + 普通 RLM(36.1%),快 3.1 倍。更有说服力的是按模型规模分层:
- Weak(7-8B):100% 胜率,平均 +21.9pp
- Medium(22-32B):92% 胜率
- Strong(235B+):50% 胜率
弱模型获益最大,因为它们最受不可靠控制流之苦;强模型已经能写出好的递归代码,符号化约束反而限制了灵活性。
这条路径和前两条的关系是正交的——lambda-RLM 不增加搜索深度(它的 LLM 调用次数可能和直接推理一样多),也不压缩 token(每个叶子节点仍然需要完整的推理输出)。它的效率来源是避免了无效的控制流尝试。
三条路径的关系:互补而非竞争
| 路径一:搜索深度 | 路径二:信息压缩 | 路径三:控制流可靠性 | |
|---|---|---|---|
| 解决什么问题 | 固定深度不足以完成复杂推理 | CoT 中大部分 token 是冗余的 | 自由生成的控制流不可靠 |
| 效率来源 | 同一参数多次执行 | 移除不贡献推理的 token | 避免无效的控制流尝试 |
| 典型方法 | Ouro, RYS, LoopRPT | CIB, ΔlogP 定位 | lambda-RLM |
| 适用场景 | 紧耦合约束满足/组合推理 | CoT 已有效但冗余的场景 | 可分解的长上下文任务 |
| 核心限制 | 规模局限(<2.6B 验证) | prior 质量依赖 | 不适用于不可分解问题 |
三条路径不是在同一个维度上的竞争方案,而是针对不同瓶颈的互补解法:
- 如果你的问题需要更深的搜索(如组合推理),走路径一
- 如果你的 CoT 已经有效但太长了,走路径二
- 如果你的模型不够强、控制流不可靠,走路径三
理论上,三条路径可以组合:一个循环 Transformer(路径一)+ CIB 训练的 CoT 压缩(路径二)+ 符号化的外部控制流(路径三),可能产生比任何单一路径更大的效率增益。但这种组合尚未被实现或验证。
与约束满足架构框架的连接
路径一(搜索深度)和之前的 约束满足架构条件 2x2 框架 有深层联系。
该框架提出约束满足需要两个正交条件:成对变量交互 + 可迭代执行。Ouro 天然同时具备两者——attention 提供成对交互,循环提供迭代。论文的 O(log D) 理论正是因为 LoopLM 在每步循环中并行更新所有变量对的连通性信息。
RYS 进一步精确化了"迭代"的含义:Transformer 的迭代不是层级粒度的(不是每层都在独立迭代),而是电路级的(5-10 层的功能块作为一个迭代单元)。这是对 2x2 框架的重要补充——框架预测了"需要迭代",但没有说明"迭代的最小有效单元是什么"。
但 lambda-RLM 暴露了 2x2 框架的一个边界条件:它的 MAP 操作假设子问题独立(各子问题不互相约束),这和约束满足中"成对交互"的核心需求完全不同。可迭代的成对交互解决紧耦合问题(如 Sudoku),可迭代的分治解决可分解问题(如长文档摘要),两者的适用范围不同。
开放问题
1. 搜索深度在大规模上还有效吗?
Ouro 的核心实验只在 1.4B-2.6B 上验证。一个合理的假说:如果更大的模型本身就有足够的层数(如 64 层 vs 24 层),可能已经具备了足够的"搜索深度",循环的边际收益消失。RYS 在 72B 上有效是一个部分反驳(72B 有 80 层,复制中间层仍然有效),但 MuSR +17.72% 的增益是否在 200B+ 上仍然存在?未知。
2. 最优迭代粒度
RYS 发现 5-10 层是有效的迭代单元,但 Ouro 循环整个模型(24/48 层)。两者都有效暗示"有效迭代粒度"可能是一个范围而非单一最优点。这个范围和模型大小、任务复杂度的关系完全未知。
3. Ouro 外推失败的含义
Ouro 训练 4 步但外推到 5-8 步时性能下降。如果迭代真的是搜索,搜索更多步不应该更差。可能的解释:训练时每步的 loss supervision 让模型优化了"4 步就给出好答案",而不是"持续搜索到收敛"。这和 约束满足 distillation 中讨论的"端到端训练 N 步导致步数特异性行为"是同一个问题。
4. 三条路径是否可组合?
理论上可以,但 lambda-RLM 的符号化控制流和 LoopLM 的隐式循环之间可能有张力——前者假设子问题独立(可分解),后者的优势恰恰在于处理紧耦合问题(不可分解)。它们最自然的组合可能是:Ouro/RYS 处理每个子问题的深度推理,lambda-RLM 负责子问题之间的分治结构。CIB 则在每个级别压缩冗余 token。但这只是推测。
5. 因果忠实性的解读
Ouro 发现 step 2 的答案只有 36.1% 和 step 4 一致——论文将此解读为"每步循环都在真正改变决策"(推理忠实性高于 CoT 的事后合理化)。但替代解释是训练不稳定——每步都给了独立的 loss supervision,模型可能在每步独立解题而非在先前基础上精炼。区分这两种解释需要更精细的实验(如去掉中间步的 loss supervision 后观察步间一致性是否改变)。
局限性
-
CIB 和 Ouro 的实验规模都较小(7B 和 2.6B)。在 70B+ 规模上的表现缺乏证据。
-
三条路径的"互补性"是推测性的。没有任何实验同时使用多条路径来验证组合效果。
-
lambda-RLM 只在长上下文任务上验证。其效率增益的来源(控制流可靠性)是否在短上下文、非分解任务上同样重要?大概不是——在短上下文下,直接推理可能足够。
-
"推理 = 知识图搜索"的隐喻可能过度简化。知识不一定组织为图,搜索不一定是深度优先/广度优先。这个隐喻在 Ouro 的受控实验中成立(模运算树确实是图搜索),但在自然语言推理中是否成立需要更多证据。
-
RL 信号稀疏性的交叉发现(Qwen 的 10% token 恢复完整性能 + PivotRL 的 71% 零信号 turns [ref])暗示"有效信号极度集中"是一个跨层级的现象。但这是否只是 exploitation in RL 的重新包装?经典 RL 理论虽然知道信号集中,但没有量化 LLM 设定下的具体程度。CIB 和 PivotRL 的贡献在于具体的量化和定位方法。
总结
推理效率不是一个单一维度的问题。它至少包含三个独立的瓶颈:
-
搜索深度:固定深度的 Transformer 在复杂组合推理上有结构性限制。循环架构(Ouro)和电路复制(RYS)通过让同一参数多次执行来增加搜索深度。Ouro 的知识容量实验提供了一个重要的理论分离:推理增益来自知识操作的增加,而非知识存储的增加。
-
信息压缩:CoT 的大部分 token 是冗余的。CIB 通过 semantic surprisal 差异化 token cost,实现了选择性压缩。Qwen 的 ΔlogP 方法从梯度机制角度确认了同一现象。
-
控制流可靠性:弱模型的推理瓶颈往往不是计算不足,而是自由生成的控制流不可靠。lambda-RLM 通过符号化控制流外部化获得了形式化保证和大幅效率提升。
三条路径的适用范围不同(紧耦合推理 vs 冗余压缩 vs 可分解任务),理论上可以组合使用,但组合效果尚未验证。
基于 5+ 篇 blog 的调研:Ouro/LoopLM [ref], RYS [Part 1] [Part 2], LoopRPT [ref], CIB/Reasoning as Compression [ref], lambda-RLM [ref], Qwen RLVR Direction [ref], PivotRL [ref]
最后更新: 2026-03-25 00:15