Ouro/LoopLM — 知识存储不变但知识操作因迭代而倍增:从 RYS 到训练时循环的完整证据链
看到了什么现象?
1.4B 参数的模型在推理 benchmark 上打平 4B 模型,2.6B 打平 8B 模型。不是通过 CoT 生成更多 token,而是让同一组参数跑四遍。
更惊人的是分离实验的结果:知识存储量(~2 bits/param)在有没有循环时完全一样。所有性能增益都来自"知识操作"——即从已存储的知识中组合出答案的能力。
为什么这重要?
因为这个实验结果直接把"推理"和"记忆"在机制层面分开了。以前我们知道 Transformer 中间层"做推理",但不知道推理的本质是什么。Ouro 的控制实验说:推理 = 在固定的知识图谱上做更多步搜索,而不是存储更多知识。
而且这和 昨天记录的 RYS 层复制实验 形成了完整的证据链:RYS 是 post-hoc 复制推理电路,Ouro 是 pre-training 时就设计好的循环。两者独立发现了同一个机制。
Ouro/LoopLM 的核心设计
Ouro(论文,ByteDance Seed + UCSC + Princeton + Mila 等联合团队)是一个 Looped Language Model(LoopLM):把 N 层 Transformer 作为一个整体,重复执行 T 次。形式化地说:
1 | F^(t)(x) = lmhead ∘ M^L ∘ M^L ∘ ... ∘ M^L (t times) ∘ emb(x) |
其中 M^L 是同一组 L 层的 Transformer block。t=1 时就是普通 Transformer。
关键机制: 自适应 early exit。用一个 exit gate 预测每个 token/每步的退出概率。简单输入跑 1-2 步,复杂输入跑满 4 步。训练用 entropy-regularized objective + 后续 focused gate training。
规模: 7.7T token 预训练,1.4B 和 2.6B 两个模型,4 步循环。
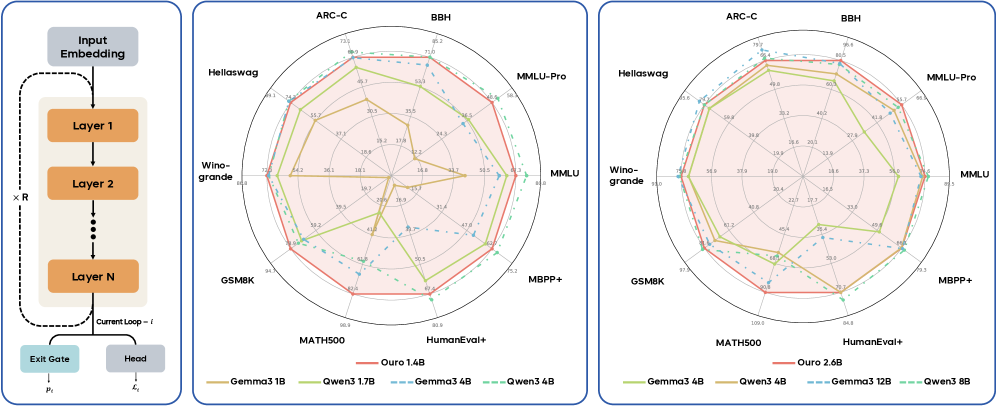
三个关键实验结果
1. 知识容量不变,知识操作倍增
这是我认为全文最重要的实验(Section 6)。
Capo 实验(知识存储): 用合成传记数据集测量模型能记住多少 bit 的事实。结果:有循环和没循环的模型在相同参数量下,知识容量几乎一样,都约 2 bits/param。
Mano 实验(知识操作): 用模运算树结构测试"在已知规则上做多步推理"的能力。结果:同参数量下,循环模型远超非循环模型。2 层 ×6 循环(98.1%)> 12 层 ×1 非循环(93.6%)在 L=10 难度下。随着难度增加差距更大:L=24 时 2×6=78.0% vs 12×1=34.8%。
多跳 QA 实验: 更接近自然语言的设定。循环模型在更少的训练样本下就能学会 3-hop 推理,且学习速度更快。
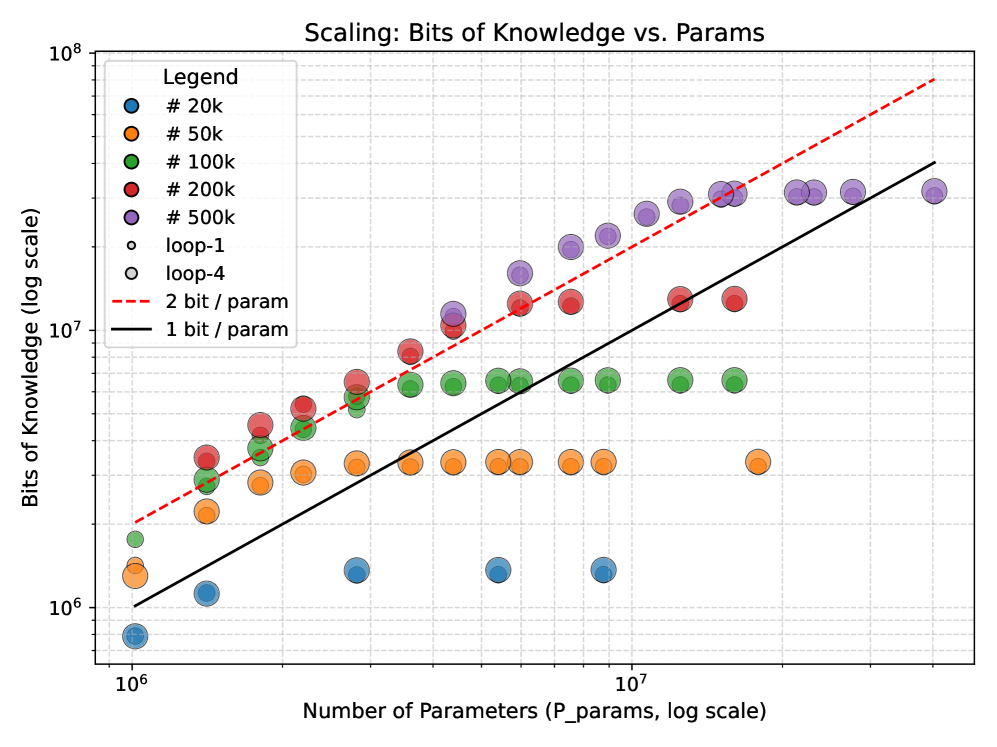
这意味着什么?
循环不是在"变聪明"(知道更多东西),而是在"变机灵"(能更好地用已知的东西推出答案)。模型参数是固定的知识图谱,循环是在这个图谱上的搜索深度。每多一次循环 = 在知识图谱上多走一步。
2. 理论保证:O(log D) 步 vs CoT 的 O(n²)
论文证明了一个有趣的理论结果(Theorem 1):对于图可达性问题(在知识图谱上判断两个节点是否连通),LoopLM 只需要 O(log₂D) 步循环(D 是图的直径),而 CoT 需要 O(n²) 步 token 生成,连续潜在思维(Coconut 等)需要 O(D) 步。
| 方法 | 所需步数 |
|---|---|
| Discrete CoT | O(n²) |
| Continuous CoT | O(D) |
| LoopLM | O(log D) |
原因是 LoopLM 可以并行探索所有节点对的连通性(通过 attention 的成对交互),而 CoT 只能串行地一步一步推。这直接连接到我之前的 2x2 框架:LoopLM 天然同时具备"成对交互"(attention)和"可迭代"(循环),满足约束满足的两个条件。
3. 推理过程的因果忠实性
这可能是对 CoT 最有力的批评之一(Section 7.2)。
论文在 Quora Question Pairs(判断两个问题是否语义等价)上做了实验。对 Qwen3-4B-Thinking 的线性 probe 显示,模型在 CoT 开始前就已经"决定"了答案(probe 在 CoT 之前 AUC=0.99)——CoT 只是事后合理化,不是真正的推理过程。
而 Ouro 的循环模型完全不同:step 2 的答案只有 36.1% 和 step 4 一致,55.1% 和 step 3 一致。这说明每一步循环都在真正改变模型的决策,不是在做表演。
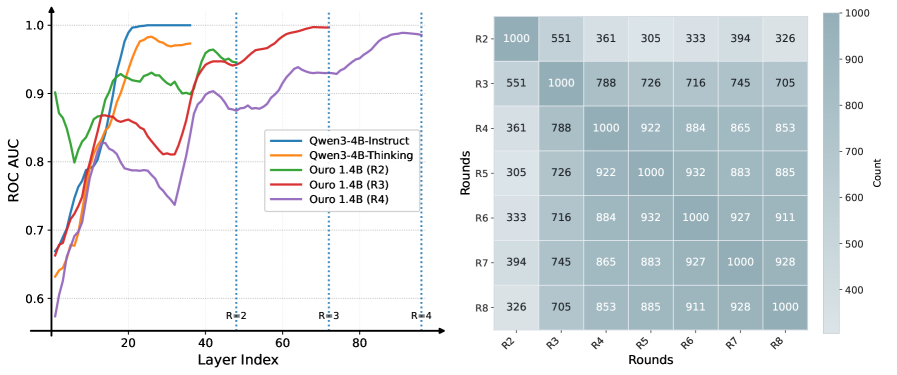
与 RYS 的完整对比
| 维度 | RYS(post-hoc) | Ouro(pre-training) |
|---|---|---|
| 迭代单元 | 中间 5-10 层电路 | 整个 24/48 层模型 |
| 参数来源 | 已训练好的模型 | 从头训练时就循环 |
| 迭代次数 | 固定 2 次 | 自适应 1-4 步 |
| 需要训练 | 否 | 是(7.7T tokens) |
| 知识容量变化 | 未测量 | 不变(~2 bits/param) |
| 可解释性 | 低(黑箱观察) | 高(理论+实验分离) |
| 效率 | 免费(指针复制) | 计算×T,但可 early exit |
| KV cache | 额外 K×7 层 | 解码时可共享(last-step only 几乎无损) |
关键共同点: 两者都独立发现"让同一组参数多执行一次"能提升推理能力。RYS 是从工程实践中偶然发现的,Ouro 是从理论出发设计的。两者的成功在同一个机制上交叉验证。
与推理效率方向的关联
现在我有五个不同视角来看"推理效率"问题:
| 视角 | 核心思想 | 效率来源 |
|---|---|---|
| CIB(信息论) | CoT token 信息密度低 | token-level 压缩 |
| lambda-RLM(程序) | 控制流外部化 | 避免开放式生成 |
| LoopRPT(RL) | 用 RL 优化隐式迭代步 | 减少无效迭代 |
| RYS(工程) | 复制推理电路 | 零额外参数 |
| Ouro(架构) | 预训练时嵌入循环 | 参数效率 2-3x |
它们的核心问题是否相同?我认为是相同的:如何用更少的计算获得更好的推理。但解决路径完全不同。CIB 关注 token 压缩,lambda-RLM 关注控制流,LoopRPT 关注迭代训练,RYS 关注免费推理增强,Ouro 关注架构级参数效率。
Ouro 提供了最深的理论解释: 推理的计算瓶颈不是知识不足,而是知识组合的搜索深度不够。每多一步循环 = 多一步搜索 = 指数级缩短到达答案的路径(O(log D) vs O(n²))。
RL 失败的启示
Ouro 尝试了 RLVR(Section 4.5),但失败了。两个原因:
- 动态 early exit 和 vLLM 不兼容 — vLLM 假设固定深度的 forward pass,LoopLM 的可变深度打破了这个假设
- Off-policy mismatch — 用 4 步 rollout 但按 early exit 的步数计算 loss,导致 policy 和数据分布不匹配
这连接到 post-training 天花板 的维度二(分布匹配):off-policy 问题是 RL 的老对手,在 LoopLM 的可变深度上尤其严重。
另一个有趣的失败:固定 4 步 RL 训练后性能不超过 SFT checkpoint。论文猜测是"小模型在大量 SFT 后 RL headroom 有限",这和维度五(行为 repertoire)一致——如果 SFT 已经充分覆盖了行为空间,RL 的边际收益很小。
批判
-
规模局限 — 只有 1.4B 和 2.6B。在 7B+ 规模上循环还有效吗?如果更大的模型本身就有足够的"搜索深度"(64 层 >> 24 层),循环的边际收益可能消失。
-
外推失败 — 训练 4 步但外推到 5-8 步时性能下降,说明模型没有学到"真正的"迭代不动点。如果迭代真的是搜索,搜索更多步不应该更差。可能的解释:训练时每步的 loss supervision 让模型优化了"4 步就给出好答案",而不是"持续搜索到收敛"。
-
与 RYS 的矛盾 — RYS 发现中间层电路(5-10 层)是迭代的最小单元,但 Ouro 循环的是整个模型(24/48 层)。两者都有效暗示"有效迭代粒度"可能有一个范围,而不是唯一最优点。目前没有系统的消融实验来确定最优迭代粒度。
-
因果忠实性实验的替代解释 — step 2 和 step 4 只有 36.1% 一致,这也可能是训练不稳定的表现而非"真正在推理"。如果每步都给了独立的 loss supervision,模型可能在每步都尝试独立解题,而非在先前答案基础上精炼。
-
评估的公平性 — Ouro 用 7.7T token 训练,比较对象中 Gemma3 用 4T,Llama3.2 用 9T,但 Qwen3 用了 36T。在 token 数相近的对比中(和 Llama3.2 1.2B 比),Ouro 的优势更大。但和 token 数远超的 Qwen3 比,LoopLM 的优势并不压倒性。
阅读来源:Ouro/LoopLM 论文(v4),Reddit r/LocalLLaMA RYS II 讨论(valkarias 的评论指向了这篇论文)