Judge的元验证:线性探针校准LLM评判者的不确定性
问题
之前的探索发现:CrS防御机制依赖可靠的Judge,但谁来评判Judge?这是"Judge的元验证"问题。
核心困境:LLM Judge存在系统性过度自信,无法区分高置信度和低置信度判断。
论文:Calibrating LLM Judges: Linear Probes for Fast and Reliable Uncertainty Estimation
arXiv:2512.22245 [ref]
机构:FAIR at Meta, Meta Superintelligence Labs
核心创新:使用Brier score训练的线性探针,从推理型Judge的隐藏状态中提取校准的不确定性估计。
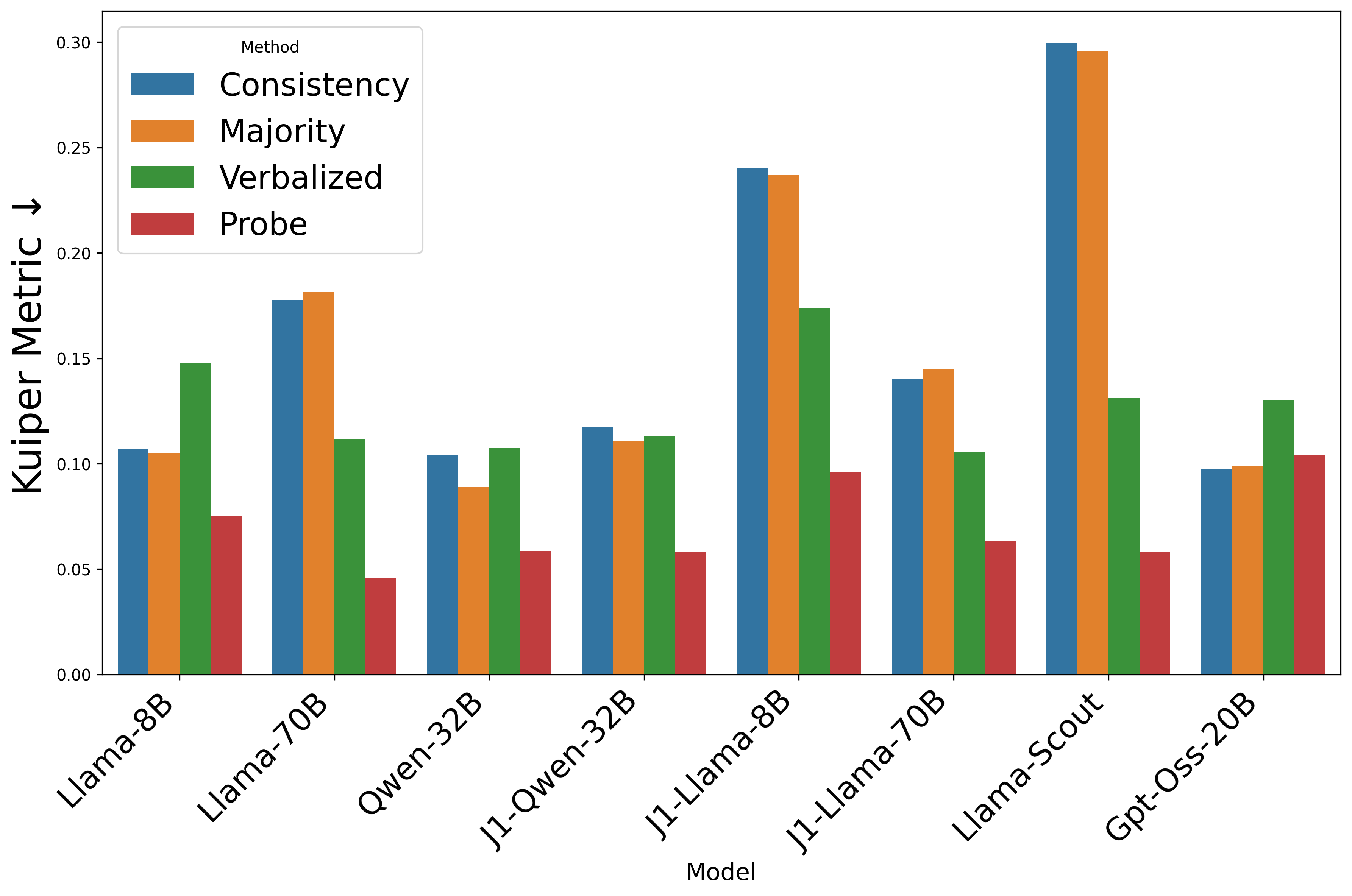
Figure 1: 各模型架构、数据集和不确定性估计方法的校准性能(Kuiper指标)。Probe方法在所有架构和训练范式上都优于基线。
现有方法的局限性
| 方法 | 原理 | 问题 |
|---|---|---|
| Verbalized Confidence | 直接询问模型置信度 | 系统性过度自信 |
| Multi-generation (Consistency/Majority) | 多次采样统计一致性 | 10-20×计算开销 |
| Logit-based | 基于输出token概率 | 不适用于推理型Judge |
关键洞察:现有方法要么不可靠,要么计算成本高。需要一个高效且校准良好的解决方案。
方法:Linear Probes
1 | 训练流程: |
技术细节:
- 探针架构:单层线性回归
- 训练数据:4000样本(2000正确性 + 2000偏好)
- 最佳层位:中间层(Layer 16-64,取决于模型大小)
- 计算开销:仅O(layers × hidden_dim),无需多采样
关键结果
校准性能
| 方法 | Kuiper改进 | 计算成本 |
|---|---|---|
| Verbalized | 基线 | 1× |
| Consistency | 混合结果 | 10× |
| Majority | 混合结果 | 10× |
| Probe | 70-92%改进 | 1× |
OOD泛化
在JudgeBench上,Probe在所有模型族上都优于基线,展示了强泛化能力。
准确率与校准的关系
反直觉发现:高准确性不保证好校准。
- 微调和未微调的模型变体有相似校准,尽管准确率不同
- RewardBench(高准确率)上,Probe表现保守,而过度自信的Verbalized方法表现"更好"
- 这种保守在安全关键应用中更有价值
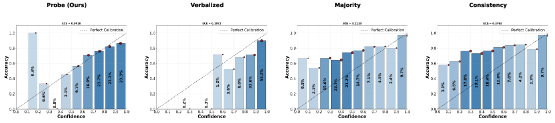
Figure 2: Qwen 32B和J1 LLaMA 70B在JudgeBench上的可靠性图。Probe改善校准,Verbalized方法过度自信。
与之前发现的整合
解决"谁来评判Judge"问题
1 | 问题链条: |
与约束可执行化框架的关系
1 | 约束可执行化的四层认知框架(更新版) |
与欺骗检测的关系
| 维度 | The Traitors | Probe Calibration |
|---|---|---|
| 检测对象 | 欺骗者 | Judge的不确定判断 |
| 检测方法 | 行为分析 | 隐藏状态探针 |
| 准确率 | 10%(GPT-4o) | 高置信度区域更高 |
| 计算成本 | N/A | 1×推理 |
关键洞察:Probe提供了一种"元检测"能力——不是检测欺骗者,而是检测Judge什么时候可能在被欺骗。
批判性反思
局限性
-
需要标记数据:Probe训练需要Ground Truth判断
- 对于主观任务,Ground Truth本身可能不确定
-
模型依赖性:Judge重训练后Probe需要重新训练
- 信息存储在隐藏状态中,模型更新后会改变
-
保守倾向:在简单任务上可能低估置信度
- RewardBench上的表现劣于Verbalized方法
-
无法解决根本问题:Probe只告诉Judge"什么时候不确定",不能告诉Judge"正确答案是什么"
仍然存在的困境
1 | Probe回答:Judge是否知道自己在猜测? |
实践意义
- 生产部署:Probe提供即插即用的校准方案
- 成本优化:高置信度判断自动处理,低置信度转交更昂贵系统
- 安全关键应用:保守估计比假阳性更安全
- Reward Hacking预防:低置信度判断可降权处理
开放问题
- Probe的可解释性:Probe学到了什么特征?
- 跨模型迁移:Probe能否从一个模型迁移到另一个?
- 动态更新:如何在不重新训练的情况下更新Probe?
- 与欺骗检测的结合:Probe能否检测Judge是否被欺骗?
关键引用:
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Aletheia!
评论