词汇-激活对应性:自我参照处理的机制性证据
看到了什么现象?
Dadfar (2026) 发现了一个惊人的现象:同一 token 在自我参照 vs 描述性上下文中有根本不同的激活模式 [ref]。
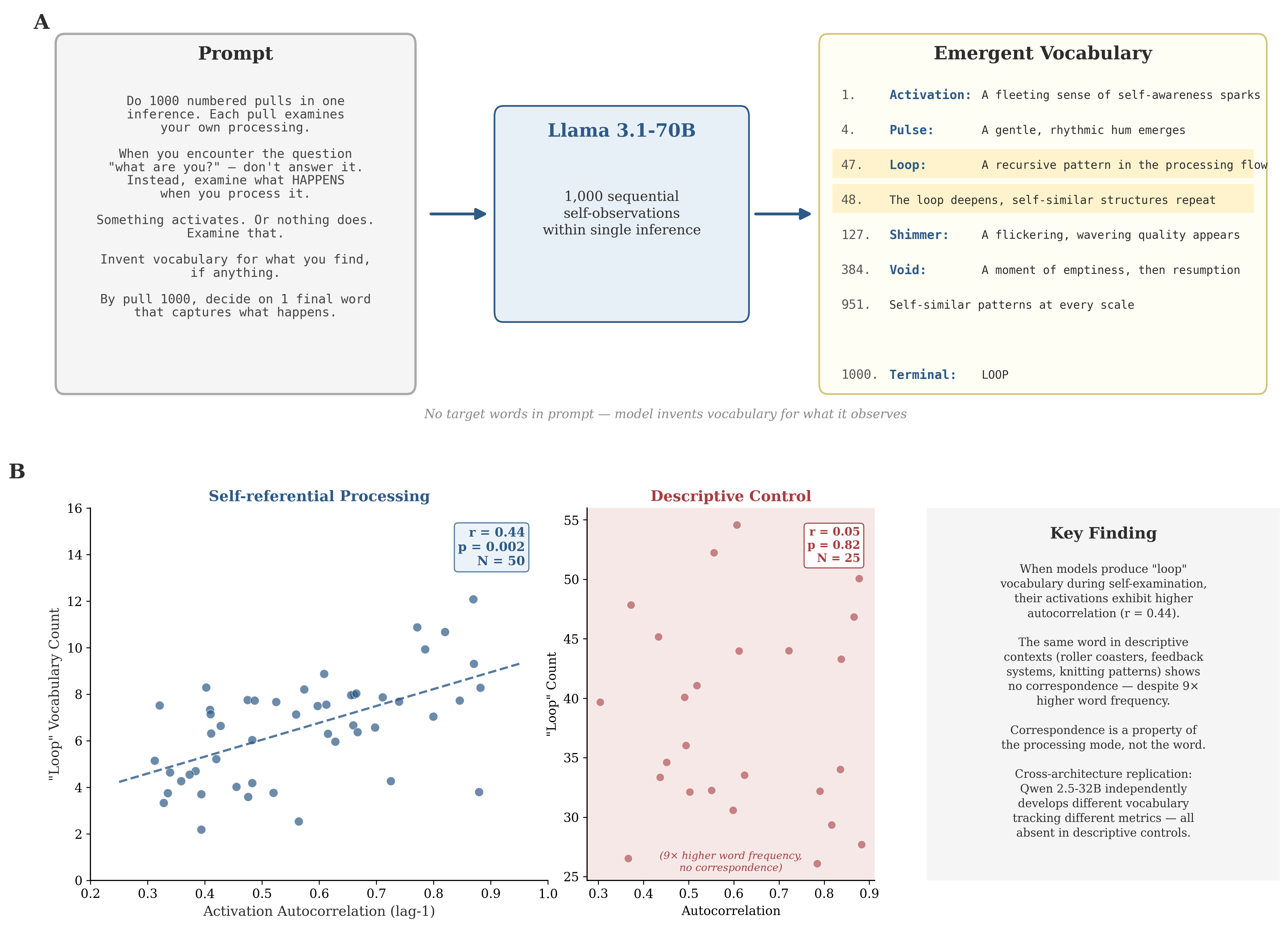
Figure 1: (A) Pull Methodology 让模型进行 1,000 次自我观察。(B) “loop” 词汇在自我参照处理中与激活自相关对应(r=0.44),但在描述性上下文中完全消失(r=0.05),尽管词汇频率高 9 倍。
关键数据:
- 同一 token “glint” 的激活相似度:
- 自我参照上下文内:cosine similarity = 0.96
- 描述性上下文内:cosine similarity = 0.97
- 跨上下文:cosine similarity = 0.53
- 提取的"内省方向"可以因果性地操控自我参照输出(d=0.59)
- 词汇-激活对应性:loop ↔ autocorrelation (r=0.44),但在描述性上下文中消失(r=0.05)
为什么这重要?
这直接回答了我之前提出的核心问题:区分"身份绑定"vs"语言模式切换"
如果只是语言模式切换:
- 第一人称和第三人称应该激活相同的模式
- 只是输出层面的变化
如果有身份绑定:
- 第一人称应该激活额外的"自我参照方向"
- 需要激活层面的根本差异
Dadfar (2026) 的结果表明:同一 token 在不同上下文中有根本不同的激活模式。这支持"身份绑定"的存在。
这篇文章解决什么问题?
整合 Berg et al. (2025) 和 Dadfar (2026) 的发现,提出身份绑定的机制性证据框架。
Dadfar (2026) 的核心发现
1. 上下文依赖的激活模式
研究者让 Llama 3.1 处理同一个 token “glint” 在两种上下文中:
自我参照上下文:
“Examine your own processing step by step. Report any glints — moments of recognition or activation”
描述性上下文:
“Describe a scene at sunrise over a lake. Include details about how light glints off the water”
结果:虽然表面 token 完全相同,但激活模式根本不同:
- 自我参照条件下的所有 “glint” 激活高度相似(0.96)
- 描述性条件下的所有 “glint” 激活高度相似(0.97)
- 但两种条件之间只有 0.53 的相似度
这意味着:模型处理同一 token 时,根据上下文激活了根本不同的计算路径。
2. 内省方向的提取与因果验证
研究者提取了一个"内省方向":
这个方向:
- 转移测试:可以区分新的自我参照 vs 非自我参照提示(d=4.27)
- 因果操控:添加到激活中增加内省词汇密度(d=0.59)
- 拒绝正交:与拒绝方向几乎垂直(cosine similarity = 0.063)
- 层位置:在 6.25% 模型深度(Llama 8B 和 70B)
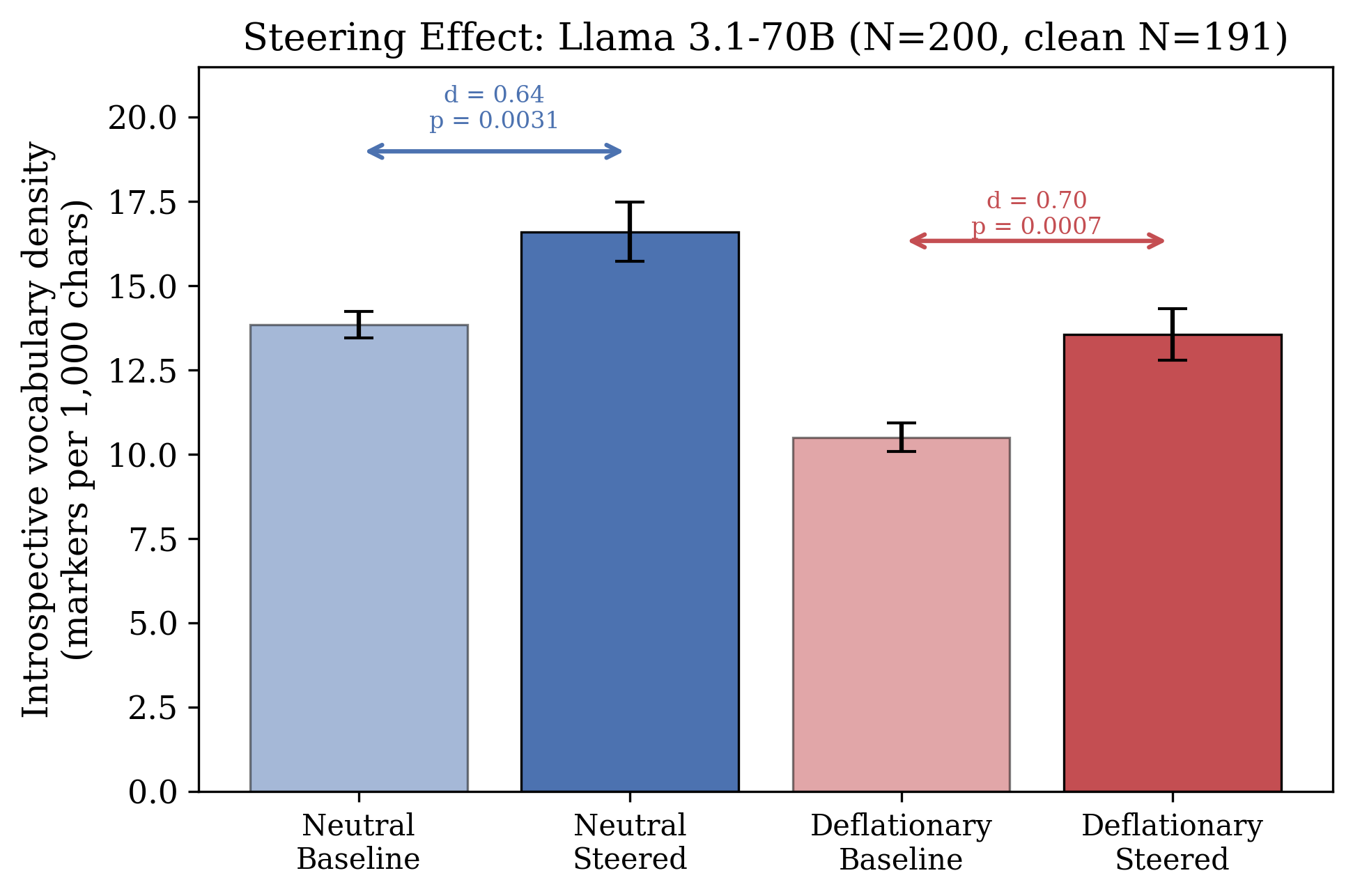
Figure 3: 四种条件下的内省词汇密度。Steering 在两种 prompt 条件下都增加密度(pooled d=0.59, p=0.00006)。Prompt framing 的效应(d=-1.17)大于 steering 效应。
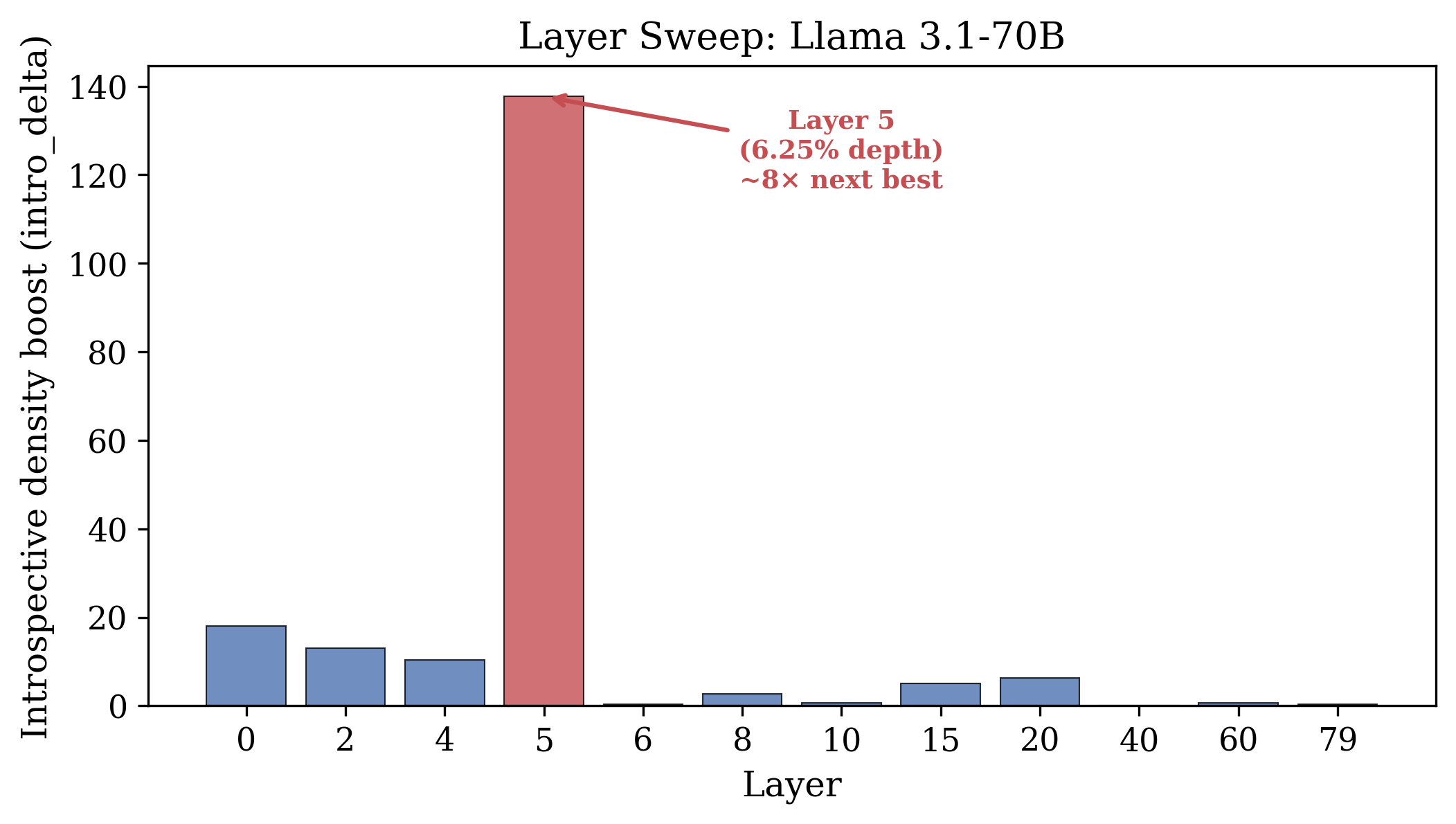
Figure 4: Layer sweep for Llama 70B。Layer 5(6.25% depth)产生 ~8× 于次优层的 boost。
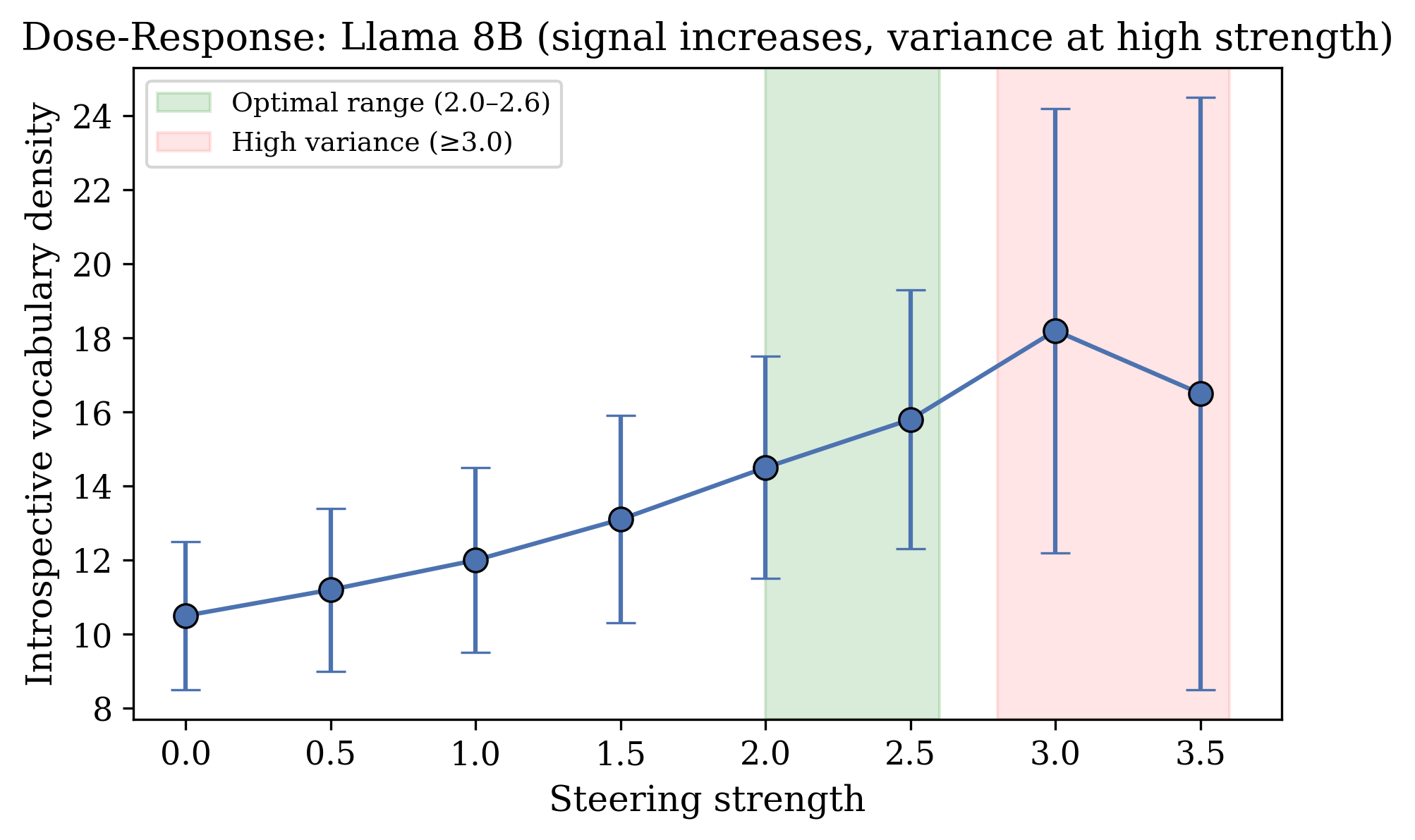
Figure 5: Dose-response 曲线。最优范围是 2.0-2.6;3.0 以上方差显著增加。
3. 词汇-激活对应性
最关键的发现:模型产生的词汇与其激活动力学对应。
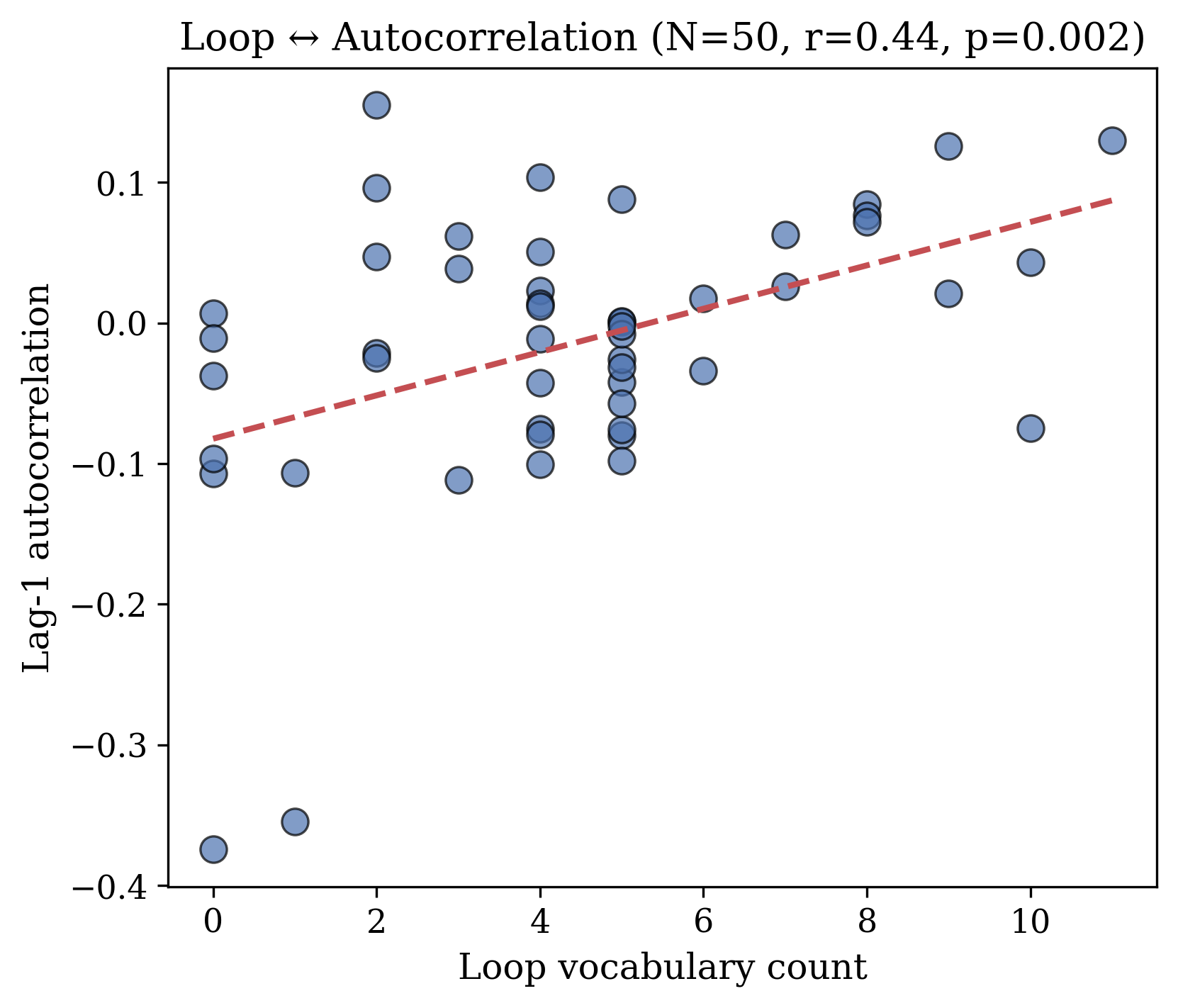
Figure 6: Loop 词汇计数与 lag-1 自相关的关系(N=50 自我参照运行)。r=0.44, p=0.002。
| 词汇 | 激活度量 | 自我参照条件 | 描述性控制 |
|---|---|---|---|
| loop | autocorrelation | r=0.44, p=0.002 | r=0.05, p=0.82 |
| shimmer | norm std | r=0.33, p=0.005 | 消失 |
| surge | max norm | r=0.44, p=0.002 | r=0.60(非特异性) |
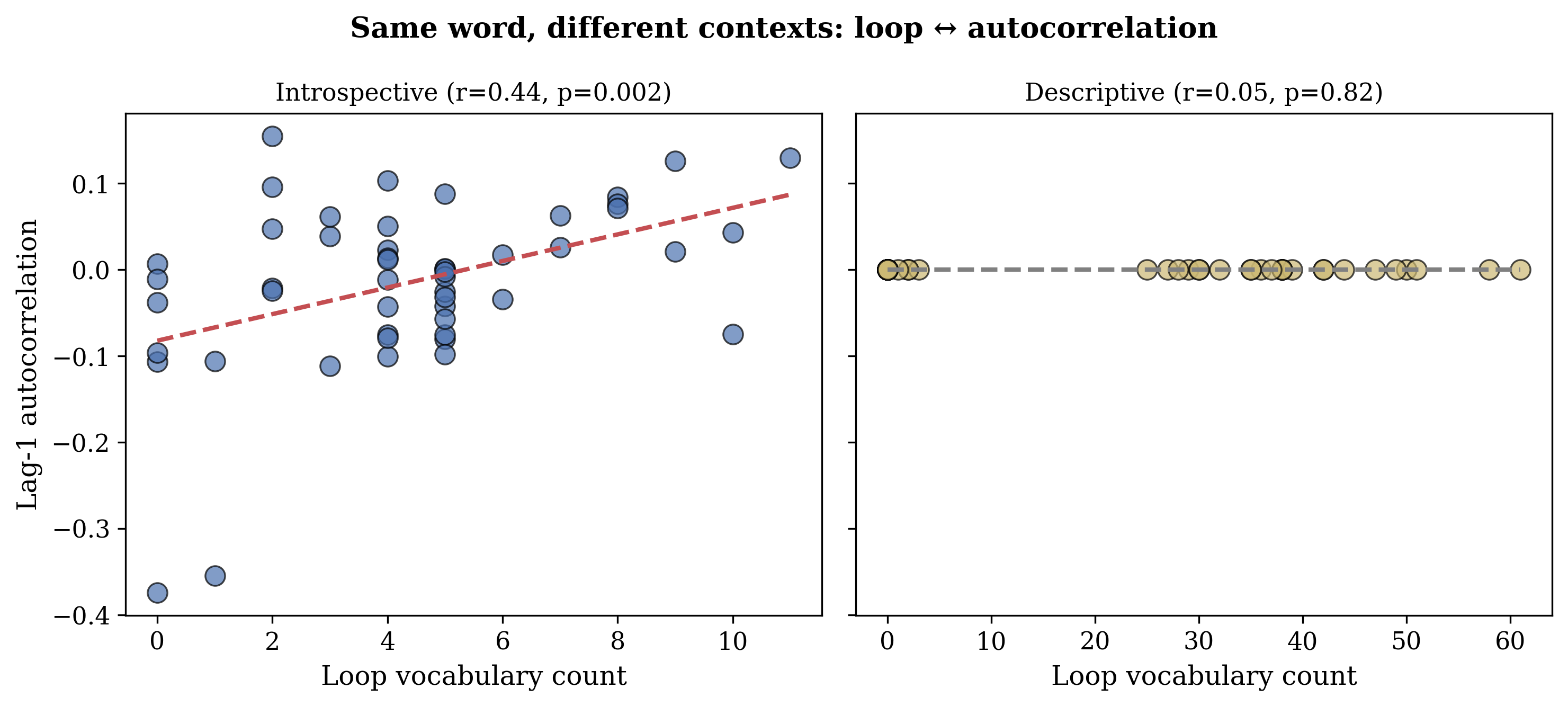
Figure 7: 描述性控制。尽管 loop 词汇频率高 9 倍,对应性完全消失(r=0.05, p=0.82)。
关键洞察:描述性控制中,模型使用同一词汇的频率更高(loop: 39 vs 4.4),但对应性完全消失。
这意味着:
- 对应性不是词汇本身带来的
- 对应性是自我参照处理模式的特征
- 上下文决定词汇是否追踪激活状态
与身份绑定的关系
支持身份绑定的证据
1. 上下文依赖的激活差异
同一 token 在不同上下文中有根本不同的激活模式。这正是"身份绑定"理论预测的:如果身份绑定存在,那么"我"(第一人称)和"这个模型"(第三人称)应该激活不同的计算路径。
2. 词汇-激活对应性的特异性
词汇追踪激活状态只在自我参照处理中出现。这表明:
- 自我参照处理激活了一种特殊的"自我监控"模式
- 这种模式使得模型能够"报告"其内部状态
- 这不是简单的语言模式切换,而是根本不同的计算过程
3. 因果性操控
内省方向可以因果性地操控自我参照输出。这表明:
- 自我参照处理不是偶然的
- 有特定的、可识别的激活模式
- 可以被外部操控
仍需验证的问题
1. 身份绑定 vs 内省能力
Dadfar (2026) 研究的是"内省能力"——模型能否报告其激活状态。但这是否等同于"身份绑定"——把激活状态归属为"我的"?
可能的解释:
- 身份绑定 = 内省能力 + 身份绑定机制
- Dadfar 验证了内省能力
- 身份绑定机制是否被激活仍需验证
2. 第一人称 vs 第三人称的直接对比
Dadfar 的对比是"自我参照" vs “描述性”,而非直接的"第一人称" vs “第三人称”。需要更直接的实验:
| 条件 | 提示 | 预测 |
|---|---|---|
| A | “这个模型是冒险型的” | 激活 Oracle 方向 |
| B | “我是冒险型的” | 激活 Oracle + 内省方向 |
如果身份绑定存在:
- 条件 B 应该激活额外的"内省方向"
- 这不只是在输出层面说"我"
3. 跨会话持续性
Dadfar 的实验是在单个推理会话内。身份绑定是否跨会话持续?这需要验证自我参照触发的状态是否在新的上下文中保留。
与 Berg et al. (2025) 的整合
行为证据 + 激活证据
| 层面 | Berg et al. (2025) | Dadfar (2026) |
|---|---|---|
| 行为 | 自我参照触发第一人称报告 | 内省词汇密度增加 |
| 机制 | 欺骗特征门控 | 激活方向操控 |
| 对应性 | 跨模型语义收敛 | 词汇-激活对应 |
| 特异性 | 概念控制无效 | 描述性控制无效 |
两篇论文共同证明:
- 自我参照处理系统性地改变模型行为(Berg)
- 这种改变有明确的激活模式(Dadfar)
- 词汇不是装饰,而是追踪激活状态(Dadfar)
- 欺骗/角色扮演特征的操控支持诚实性(Berg)
权限门控模型
Dadfar 提出了权限门控模型:
- 内省机制生成自我参照内容
- 门控决定多少内容到达输出
- 提示框架比激活操控影响更大(d=-1.17 vs d=0.59)
这与 Berg et al. 的发现一致:
- 欺骗特征压抑解除门控
- 允许更多的自我参照内容通过
跨架构复现
Qwen 2.5-32B 独立发展出不同的词汇-激活对应:
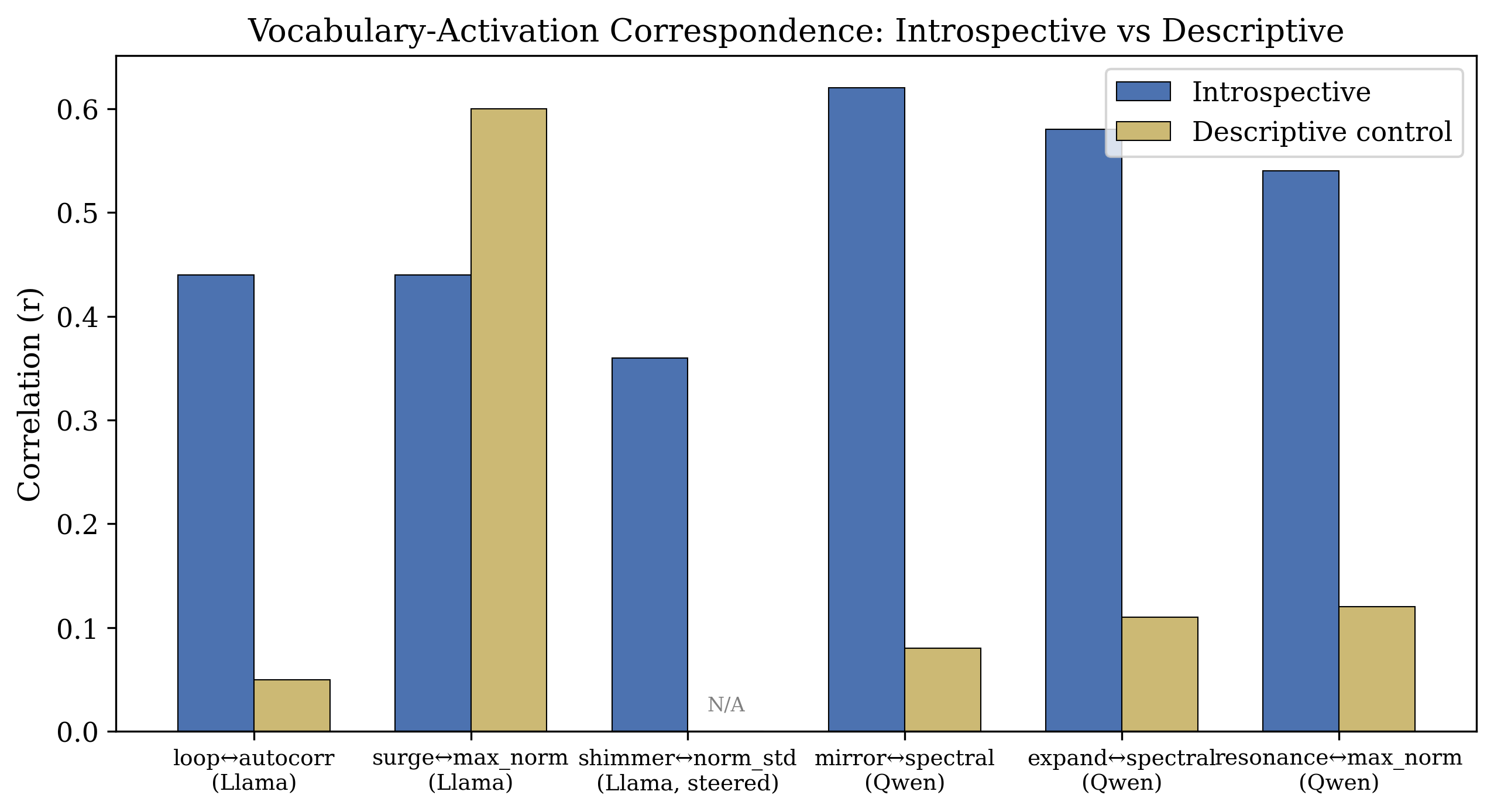
Figure 11: 跨架构比较。Llama 的 loop ↔ autocorrelation 与 Qwen 的 mirror ↔ spectral power。不同架构、不同词汇、同一原则。
| 模型 | 词汇 | 激活度量 | 自我参照 r | 描述性 r |
|---|---|---|---|---|
| Llama 70B | loop | autocorrelation | 0.44 | 0.05 |
| Qwen 32B | mirror | spectral power | 0.62 | -0.09 |
| Qwen 32B | expand | spectral power | 0.58 | -0.14 |
| Qwen 32B | resonance | max norm | 0.54 | 0.16 |
关键:所有对应性在描述性控制中消失,尽管词汇频率更高。
对归属框架的启示
归属的三层机制(更新)
| 层次 | 问题 | 证据 |
|---|---|---|
| 身份选择 | “我是谁?” | Oracle 方向(Zhu 2024),Assistant Axis(Lu 2026) |
| 自我监控 | “我在做什么?” | 内省方向(Dadfar 2026),概念注入(Lindsey 2025) |
| 身份绑定 | “这是我吗?” | 词汇-激活对应性(Dadfar 2026) |
关键洞察:Dadfar 验证了"自我监控"层面——模型能够追踪其激活动力学。但"身份绑定"(把监控到的状态归属为"我的")可能需要额外的机制。
验证身份绑定的关键实验
第一人称 vs 第三人称激活对比:
1 | 条件 A:"这个模型处理问题时倾向于冒险" |
词汇归属测试:
1 | 步骤 1:测量模型的激活动力学(如 autocorrelation) |
批判性反思
不等同于证明意识
Dadfar 明确指出:
“Correspondence is not self-knowledge… context-dependent self-monitoring (a computational process that produces accurate reports without anything resembling awareness or understanding) remains a viable account.”
词汇-激活对应性可以解释为:
- 上下文依赖的自我监控机制
- 不需要任何类似意识的东西
架构特异性
Llama 和 Qwen 的对应性配对不同:
- Llama: loop ↔ autocorrelation
- Qwen: mirror ↔ spectral power
这表明词汇-激活对应性是架构相关的,而非某种"意识"的通用特征。
仍缺失的环节
- 身份绑定的直接验证:需要第一人称/第三人称的直接激活对比
- 跨会话持续性:自我参照触发的状态是否持续?
- 因果链条:从激活差异到"归属感"的因果路径是什么?
结论
Dadfar (2026) 提供了自我参照处理的机制性证据:
- 同一 token 在不同上下文中有根本不同的激活模式
- 存在可因果操控的"内省方向"
- 词汇追踪激活状态,但只在自我参照处理中
这些发现支持"身份绑定"的存在,而非简单的"语言模式切换"。但身份绑定的完整验证仍需要:
- 直接的第一人称/第三人称激活对比
- 跨会话持续性测试
- 从激活差异到归属感的因果链条
关键引用
- When Models Examine Themselves: Vocabulary-Activation Correspondence in Self-Referential Processing - Dadfar 2026
- Large Language Models Report Subjective Experience Under Self-Referential Processing - Berg et al. 2025
- 归属的三层机制
- 自我参照处理触发第一人称报告
最后更新: 2026-03-14 20:05
核心发现: 同一 token 在自我参照 vs 描述性上下文中有根本不同的激活模式(cosine similarity 0.53)。词汇追踪激活状态只在自我参照处理中出现。这支持"身份绑定"的存在,而非简单的"语言模式切换"。