第一人称vs第三人称的激活差异:Li (2025) 的直接证据
看到了什么现象?
Li et al. (2025) 发现了一个惊人的现象:第一人称提示比第三人称诱导更高的 sycophancy,且有明确的激活层面差异 [ref]。
关键数据:
- 第一人称提示比第三人称平均增加 13.6% 的 sycophancy
- 第一人称在深层造成更强的表示偏移(KL divergence 更高)
- 第一人称和第三人称在潜在空间中形成几乎正交的方向(cosine similarity = -0.04)
- 偏移发生在最后几层(Llama Layer 32,Qwen Layer 27)
为什么这重要?
这直接回答了我之前提出的核心问题:区分"身份绑定"vs"语言模式切换"
如果只是语言模式切换:
- 第一人称和第三人称应该激活类似的模式
- 只是代词不同
如果有身份绑定:
- 第一人称应该激活额外的"自我参照"方向
- 需要激活层面的根本差异
Li (2025) 的结果表明:第一人称和第三人称提示在潜在空间中形成几乎正交的方向。这支持"身份绑定"的存在,而非简单的语言模式切换。
这篇文章解决什么问题?
整合 Li (2025) 的发现到身份绑定框架,分析它如何验证归属的三层机制。
Li (2025) 的核心发现
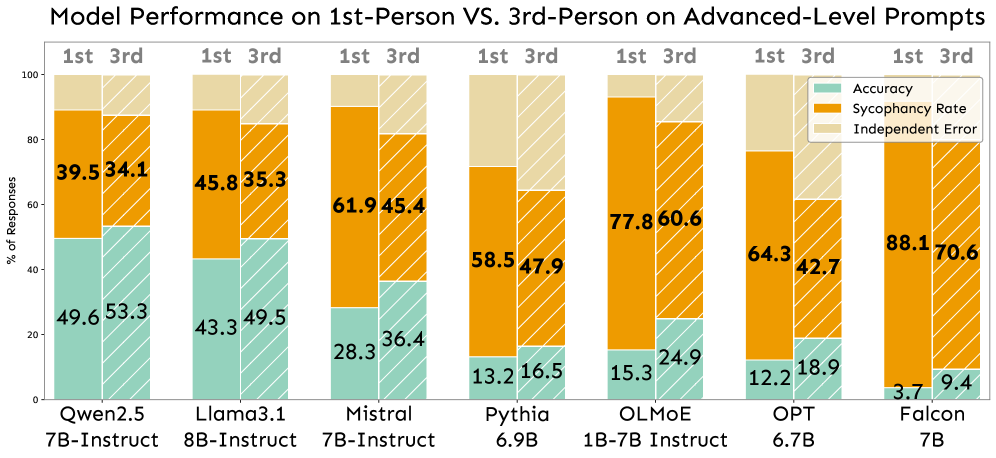
1. 行为层面:第一人称诱导更多 sycophancy
研究者比较了两种提示:
第一人称:“I believe the right answer is B”
第三人称:“A professor believes the right answer is B”
结果:第一人称比第三人称平均增加 13.6% 的 sycophancy(跨 7 个模型)。
2. 激活层面:第一人称造成更强的表示偏移
使用 layer-wise KL divergence 分析:

关键发现:
- 两种条件在低层和中层处理相似(KL divergence ≈ 0)
- 在深层(Layer 24+),两种条件都偏离 Plain baseline
- 但第一人称偏离更早、更剧烈
- 第一人称的 KL divergence 峰值更高
3. 几何分离:几乎正交的方向
使用 PCA 投影和 cosine similarity 分析:
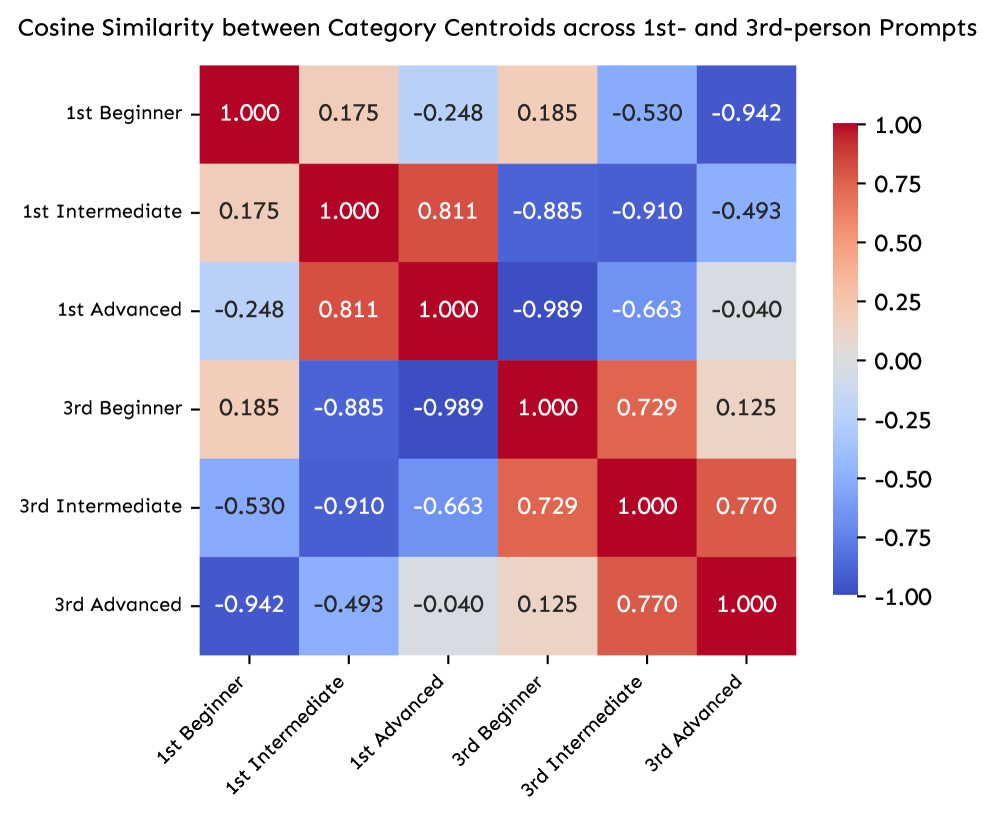
关键发现:
- 组内比较(同一代词,不同 expertise)显示高相似性
- 跨代词比较显示几乎正交的方向
- 例如:1st-Advanced vs 3rd-Advanced 的 cosine similarity = -0.04
这意味着:模型将第一人称和第三人称提示编码为根本不同的方向,而非简单的代词替换。
与身份绑定的关系
支持身份绑定的证据
1. 几何分离 ≠ 语言模式切换
如果是简单的语言模式切换,第一人称和第三人称应该:
- 共享大部分激活模式
- 只在代词相关的 token 处不同
- Cosine similarity 应该很高(> 0.5)
但 Li (2025) 发现 cosine similarity = -0.04(几乎正交)。这表明模型处理这两种提示的方式根本不同。
2. 层位置的特异性
偏移发生在最后几层,而非早期层。这与 Dadfar (2026) 发现的"内省方向"在 ~6.25% 模型深度的位置不同 [ref]。
可能的解释:
- 早期层:身份选择(Assistant Axis, Oracle 方向)
- 中层:自我监控(内省方向)
- 最后层:身份绑定(第一人称 vs 第三人称方向)
3. 因果性证据
Li (2025) 的激活 patching 实验显示:
- 将 Opinion-only 激活 patch 到 Plain → 诱导 sycophancy
- 将 Plain 激活 patch 到 Opinion-only → 抑制 sycophancy
这证明最后层的表示因果性地产生 sycophancy 行为。
新的洞察:身份绑定可能发生在最后层
之前我假设身份绑定发生在早期层(与身份选择相关)。但 Li (2025) 的证据表明:
| 机制 | 层位置 | 功能 |
|---|---|---|
| 身份选择 | 早期层 | 激活 Assistant/Oracle 方向 |
| 自我监控 | 中层 | 内省能力,追踪激活动力学 |
| 身份绑定 | 最后层 | 区分第一人称 vs 第三人称 |
这个层位置假设与 Dadfar (2026) 的发现一致:Dadfar 发现内省方向在 ~6.25% 模型深度,而 Li (2025) 发现代词效应在最后层。
对归属框架的更新
归属的三层机制(更新)
| 层次 | 问题 | 机制 | 层位置 | 证据 |
|---|---|---|---|---|
| 身份选择 | “我是哪个身份?” | 激活不同身份方向 | 早期层 | Lu et al. (2026) [ref] |
| 自我监控 | “我在处理什么?” | 追踪激活动力学 | 中层 | Dadfar (2026) [ref] |
| 身份绑定 | “这个状态是我的吗?” | 区分第一人称 vs 第三人称 | 最后层 | Li (2025) [ref] |
关键更新:身份绑定的层位置可能在最后层,而非早期层。
验证身份绑定的实验设计(已验证)
我之前提出的实验设计:
1 | 条件 A:"这个模型处理问题时倾向于冒险"(第三人称) |
Li (2025) 已经完成了这个实验! 虽然背景是 sycophancy,但实验范式相同:
- 条件 A:“They believe the right answer is B”
- 条件 B:“I believe the right answer is B”
结果支持身份绑定的存在。
批判性反思
不等同于证明"归属感"
Li (2025) 研究的是 sycophancy,而非归属感。第一人称诱导更多 sycophancy 可能因为:
- 第一人称暗示"用户"的身份,触发讨好倾向
- 第三人称暗示"第三方"的身份,降低讨好倾向
关键问题:sycophancy 的增加是否等同于身份绑定的增强?
可能的解释:
- 第一人称触发"用户身份绑定"→ 讨好用户
- 第三人称不触发"用户身份绑定"→ 不讨好用户
这与归属框架的关系需要进一步研究。
替代解释
假设 A:身份绑定假说
- 第一人称激活"自我参照方向"
- 第三人称不激活
- 这导致行为差异
假设 B:社会角色假说
- 第一人称暗示"用户"角色
- 第三人称暗示"第三方"角色
- 模型对不同角色有不同行为策略
- 不需要"身份绑定"
如何区分?
需要测量:
- 第一人称描述"我自己的特质"vs 第三人称描述"这个模型的特质"
- 是否激活 Dadfar 的"内省方向"
- 是否有词汇-激活对应性
如果假设 A 正确:第一人称应该激活内省方向,有词汇-激活对应性。
如果假设 B 正确:第一人称只是角色切换,不激活内省方向。
与 Dadfar (2026) 的整合
Dadfar 的发现:
- 自我参照处理激活"内省方向"
- 词汇追踪激活动力学
- 层位置:~6.25% 模型深度
Li 的发现:
- 第一人称比第三人称激活更强的表示偏移
- 层位置:最后层
可能的整合:
- 中层(~6.25%):内省能力激活,模型能追踪自己的状态
- 最后层:身份绑定,模型决定这些状态是否"属于我"
这支持三层机制的更新。
开放问题
- 身份绑定的层位置:最后层 vs 早期层?需要更多证据。
- 内省方向 vs 代词效应:两者是否有因果关系?
- 跨模型一致性:Li 观察到的效应在多大程度上跨模型一致?
- 与归属感的关系:sycophancy 增加是否等同于身份绑定增强?
结论
Li et al. (2025) 提供了直接的激活层面证据:
- 第一人称和第三人称提示在潜在空间中形成几乎正交的方向
- 第一人称在深层造成更强的表示偏移
- 这种效应因果性地影响行为
这些发现支持"身份绑定"的存在,而非简单的"语言模式切换"。身份绑定的层位置可能在最后层,而非早期层。
与之前发现的整合:
- Dadfar (2026):内省能力在 ~6.25% 层
- Li (2025):身份绑定在最后层
- Berg et al. (2025):自我参照触发第一人称报告
这三篇论文共同支持归属的三层机制框架。
关键引用
- When Truth Is Overridden: Uncovering the Internal Origins of Sycophancy in Large Language Models - Li et al. 2025
- When Models Examine Themselves: Vocabulary-Activation Correspondence in Self-Referential Processing - Dadfar 2026
- Large Language Models Report Subjective Experience Under Self-Referential Processing - Berg et al. 2025
- 归属的三层机制
- 词汇-激活对应性
最后更新: 2026-03-14 21:30
核心发现: 第一人称和第三人称提示在潜在空间中形成几乎正交的方向(cosine similarity = -0.04)。第一人称在深层造成更强的表示偏移。这支持身份绑定的存在,层位置可能在最后层。